
| Sommaire: |

Hyperthreading : Explications
I) Une technologie de parallélisation
Depuis le Pentium et son architecture superscalaire (capable de traiter deux instructions en même temps), l'évolution des processeurs tend vers une optimisation grandissante de la parallélisation. Derrière ce terme se cache l'idée de faire faire le maximum de travail au processeur pendant chacun de ses cycles, on comprend donc que l'enjeu soit d'importance. Par la suite, deux technologies ont été introduites pour contribuer à une meilleure parallélisation :
- les jeux d'instructions SIMD (MMX, SSE 1&2). Leur utilisation est des plus efficaces pour optenir une parallélisation optimale, mais la contrepartie réside dans une reprogrammation en profondeur des applications afin de les exploiter.
- le moteur d'exécution dans le désordre (OOO), introduit
sur l'architecture P6 et repris par NetBurst. L'OOO n'est pas à
proprement parler une technologie de parallélisation, mais elle
optimise les flux de traitement arrivant au pipeline et augmente donc
son débit. En outre, l'intérêt de cette technique
réside dans son caractère "dynamique", capable
d'accélérer les applications antérieures sans besoin
de les recompiler.
L'architecture NetBurst a introduit une nouvelle technologie de parallélisation sous la forme de l'Hyper-Threading (HT), qui permet l'exécution simultanée de plusieurs threads avec un seul processeur physique. Pour mieux comprendre en quoi elle consiste, expliquons d'abord brièvement ce qu'est un thread, et quel est son intérêt.
II) Processus et Threads
Un environnement multi-tâches tel que Windows ou Linux fait cohabiter en mémoire plusieurs programmes, sous la forme de processus et de threads. Chaque processus et chaque thread utilise une partie des ressources du système, à savoir cycles processeur et mémoire. La différence entre un processus et un thread réside dans le fait que deux processus ne peuvent travailler dans une zone mémoire commune, alors que deux threads le peuvent. En pratique, un programme ne comporte souvent qu'un seul processus, et est susceptible d'utiliser plusieurs threads.
Un thread (littéralement "une tâche") consiste ainsi en un morceau de programme dont la particularité est de s'exécuter séparément du reste du programme, à la différence d'une fonction dont le début et la fin sont définis de façon figée dans le déroulement du programme. Prenons un exemple concret afin d'illustrer l'intérêt d'un thread : vous utilisez votre logiciel de messagerie (Outlook ou autre), et vous rédigez un nouveau message. D'une façon simplifiée, le logiciel de messagerie utilise alors deux threads : un thread s'occupe de scruter vos entrées au clavier et de mettre à jour la fenêtre du nouveau message, et un autre thread vérifie de façon périodique l'arrivée de nouveaux messages. Si un seul et même thread était utilisé pour les deux actions, la rédaction de votre message serait temporairement interrompue à chaque vérification des nouveaux messages, ce qui serait fort peu ergonomique.
L'intérêt du thread réside donc dans la séparation des tâches, donnant l'impression que le programme est capable de faire plusieurs choses en même temps. L'OS traite alternativement tous les threads en cours, passant "la main" continuellement de l'un à l'autre, et donnant ainsi l'illusion d'une exécution simultanée. C'est à la charge de l'OS de répartir les threads courants sur les ressources présentes, en fonction de leur priorité et du temps qu'il leur est apparti. Ce système prend tout son sens sur une machine à plusieurs processeurs : l'OS peut ainsi affecter un ou plusieurs threads à chaque processeur, parallélisant ainsi leur exécution.
III) Le traitement des threads
Le ou les processeurs centraux sont donc amenés à traiter une série de threads, et afin de permettre cette alternance continuelle, chaque thread est associé à un contexte (ou état) qui contient entre autres l'état des registres du processeur au moment où le traitement du thread est arrêté. Chaque fois qu'un thread est traité par le processeur, son état est restauré dans les registres du processeur, permettant ainsi à celui-ci de reprendre l'exécution du thread là où il l'avait laissée. Enfin, lorsqu'un autre thread va prendre la main, ce contexte est sauvegardé.
La transition d'un thread à un autre est une opération
particulièrement coûteuse pour le processeur. La restauration
de l'état permet certes de restaurer rapidement la plupart des
registres, mais le pipeline nécessite d'être vidangé
afin de terminer les instructions du thread précédent. Opération
particulièrement pénalisante sur le Pentium 4 dont le pipeline
comprend 20 étages.
De plus, la sauvegarde de l'état ne concerne que les registres
et non les buffers annexes (TLB, caches), qui sont remplis avec le code
et les données du thread précédent ; ceux-ci doivent
donc également être nettoyés afin d'éviter
les pénalisants échecs de caches qui ne manqueront pas d'arriver
lors des premières instructions du nouveau thread.
L'Hyper-Threading a été conçu pour pallier à
ces coûteux changements d'états, et ce en intégrant
dans le noyau du processeur plusieurs contextes qui peuvent être
actifs en même temps. L'HT actuel permet ainsi la cohabitation simultanée
de deux contextes, soit deux états complets des registres du processeur
qui peuvent être utilisés en même temps. Et voilà
ce qu'est un processeur logique !
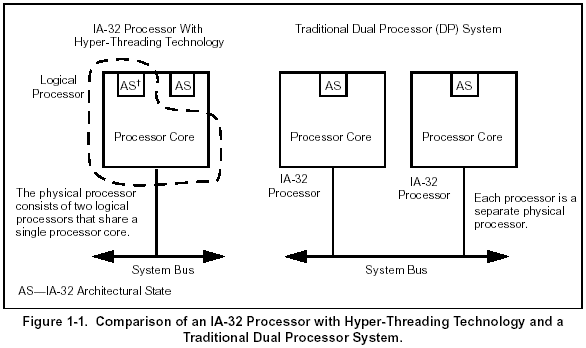
Ainsi, deux threads peuvent coexister simultanément dans le même
processeur physique, et l'OS ayant affaire à deux "destinations"
possible pour chacun des threads qu'il traite, il y voit deux processeurs,
tout comme si le système était équipé de deux
processeurs complets !
Le parallèle s'arrête là : en effet, dans le cas d'un
système à deux processeurs physiques, chaque thread bénéficie
intégralement des ressources de chaque processeur, ce qui donne
une puissance de calcul théorique égale à la somme
de celle de chaque processeur. Dans le cas de l'HT, les deux threads doivent
se partager les ressources du même processeur physique, ce qui ne
permet évidemment pas d'obtenir les performances de deux processeurs
physiques. On ne parle alors plus de système SMP (Symmetric Multi
Processing) mais de SMT (Simultaneous Multi Threading) et de processeur
logique, se sustituant à un processeur physique.
IV) Atouts et faiblesses de l'Hyper-Threading
On peut alors s'interroger sur l'intérêt du système, considérant que les deux threads sont certes susceptibles de cohabiter au même instant, mais doivent se partager les mêmes unités de calcul, ce qui à première vue semble ne pas changer grand-chose par rapport à leur traitement successif par le même processeur.
En réalité, et c'est là qu'est toute l'astuce, l'HT
exploite une faiblesse du Pentium 4, qui tient à la mauvaise utilisation
de ses ressources en utilisation courante. En effet, aux dires d'Intel,
un code classique n'utilise en moyenne que 35% des ressources réelles
du pipeline du Pentium 4, soit à peine plus d'un tiers du débit
maximal théorique ! La raison de ce faible taux réside principalement
dans la multitude de conflits qui interrompent le fonctionnement optimal
du pipeline, en particulier les conflits de dépendance et de branchement.
Avec l'HT, ce sont désormais deux flux d'instructions qui arrivent
à l'entrée du pipeline. A noter que seule la partie en amont
du pipeline est, d'une certaine façon, "consciente" de
la présence de ces deux flux provenant de deux threads différents,
et le reste du traitement s'effectue comme s'il s'agissait d'un unique
flux d'instruction. Ainsi, les deux threads se partagent les unités
de calcul et les mémoires caches.
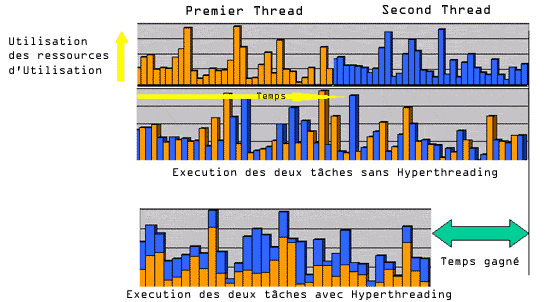
Le moteur d'exécution dans le désordre (OOO) peut alors travailler avec deux configurations de registres différentes (les deux contextes) et deux fois plus d'instructions. Son efficacité s'en trouve grandement améliorée, car il peut optimiser l'organisation des instructions envoyées dans le pipeline. En quelque sorte, les instructions du second thread comblent les "bulles" dans le pipeline, et il en résulte finalement que les unités de calcul du Pentium 4 sont mieux exploitées qu'avec un seul flux d'instructions ; Intel annonce à ce titre un gain de performance compris entre 30 et 40%.
|
Flux d'instruction classique |
Avec Hyper-Threading |
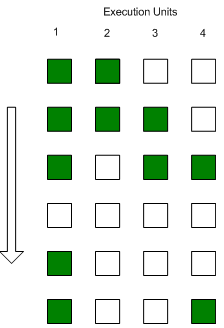
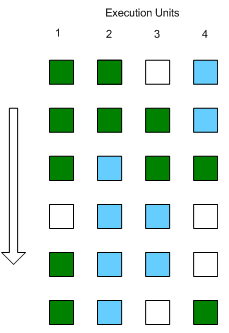
Mais si l'effet est bénéfique sur le rendement des unités
de calcul, il n'en est pas de même pour les différents buffers
internes du Pentium 4, et notamment les mémoires caches. En effet,
les deux flux d'instructions proviennent de deux threads qui sont susceptibles
de travailler sur des zones mémoires différentes, ce qui
provoque des mises en cache concurrentes entre les deux. En effet, si
un accès mémoire de la part de l'un des threads provoque
une écriture dans la mémoire cache, la ligne de cache ainsi
évincée pour faire place à la nouvelle peut éventuellement
concerner l'autre thread, lequel subira un échec de cache lorsqu'il
tentera d'y accéder.
Ainsi les deux threads gèrent les niveau de cache de façon
concurrente, ce qui peut accroître de façon conséquence
le nombre des échecs en lecture dans le cache, et ralentir ainsi
le traitement global. Il est même tout à fait envisageable
que les pénalités ainsi engendrées soient telles
que le traitement simultané des deux threads soit plus long que
les traitements successifs de chacun des threads ! Voilà pourquoi
il est possible, bien que rare, que l'utilisation de l'HT ralentisse le
traitement de certaines applications spécifiques.
La solution pour pallier à ces conflits de cache réside
dans la façon de programmer les applications multi-thread. Dans
ses guides d'aide aux développeurs, Intel recommande de gérer
les threads de telle façon que ceux ci ne considérent que
la moitié de la taille totale du cache dans le cas de deux processeurs
logiques, et par extension la taille du cache divisée par le nombre
de processeurs logiques.
Que penser donc de l'HT ? Celui-ci peut être considéré comme une amélioration à double tranchant, dans la mesure où elle est susceptible d'apporter des gains allant jusqu'à 40% pour certaines applications, mais négatifs pour d'autres applications. Tout ceci dépend en grande partie des applications, mais également du système d'exploitation, comme nous le verrons plus loin.
V) Gain théorique maximal apporté par l'Hyper-Threading
Afin de mesurer le gain théorique apporté par l'HT, et ce en comparaison à un système à deux processeurs, nous avons utilisé un programme de calcul développé spécifiquement et appelé MTB (Multi-Thread benchmark). Ce programme utilise une routine de calcul basée sur la méthode Whetstone, et composée de 10 modules distincts regroupants une série d'opérations communément effectuées par les programmes courants : manipulation de tableaux, sauts conditionnels, arithmétique entière et flottante, opérations trigonométriques, appels de fonctions. Afin d'éviter les conflits de cache, la boucle de calcul utilise des tableaux de petite taille, ce qui n'est pas réellement représentatif de conditions réelles mais permet de fournir une idée de la puissance brute de calcul.
Le programme permet de lancer simultanément jusqu'à quatre
boucles de calcul, chacune dans un thread différent. Chaque thread
peut être affecté à un des processeurs du système.
Le temps de calcul de chaque boucle est mesuré, et on peut ainsi
en déduire un index correspondant à la puissance de calcul
du système, obtenu en divisant le temps total par le nombre de
threads.
Ainsi, sur un système à deux processeur, le lancement de
deux threads, chacun affecté à un processeur, nous donne
un index de performances double par rapport à celui obtenu avec
un thread sur un processeur. Cela reflète le gain théorique
apporté par un second processeur qui est très proche de
100%. Voyons maintenant les résultats obtenus sur le Pentium 4
à 3,06GHz, avec et sans HT.
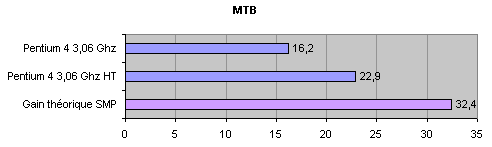
Sans HT, le Pentium 4 à 3.06GHz renvoie un index de performances de 16.2, ce qui nous donne un résultat SMP hypothétique de 32.4. Face à cela, l'utilisation de l'HT fait grimper l'index à 22.9, ce qui nous donne un gain de performance de 41% par rapport à un seul processeur, pourcentage à comparer avec les 100% que procurerait une véritable configuration SMP. Nous obtenons donc un résultat très proche des chiffres théoriques annoncés par Intel. Il convient cependant de noter que les résultats sont largement inférieurs à ceux obtenus avec une configuration SMP, face auquel l'hyper-threading est annoncé comme étant une alternative. Qui plus est, ces résultats ne reflètent pas les conditions réelles, pour lesquelles les caches représentent un facteur de performance important. Nous verrons cela lors des tests avec des benchmarks moins synthétiques que MTB.