
| Sommaire: |
![]()
32 Vs 64 Bits :
Tests Linux (1/2)
Commençons donc ces tests par la partie Linux. Comme nous l'avons dit précédemment, le but est de construire des tests les plus reproductibles possibles. Pour ce faire, nous mettrons en téléchargement tous les fichiers nécessaires à la compilation ainsi que les fichiers binaires obtenus. Pour cette première partie, nous allons nous intéressez au "High-Performance Linpack benchmark", généralement abrégé sous le nom de "Linpack", et au calcul sous Seti@Home. Principalement utilisé pour mesurer la puissance des supercalculateurs, Linpack est en fait une succession de calcul mathématique horriblement complexes. Les calculs sur d'énormes matrices complexes permettent de mesurer l'efficacité des architectures. Concernant Seti@Home, celui réalise également de très gros calcul scientifiques comme des transformations de fourier. Nous avons regroupé ces deux benchmarks ici pour une simple raison : Pour une raison inconnue, ces deux benchmarks n'ont pas pu s'exécuter sur Xeon Nocona en mode 64 bits, renvoyant un énigmatique "Illegal Instruction" avec le binaire employé. Selon plusieurs spécialistes, il s'agirait d'un bug de gcc 3.4, corrigé dans la version 4.0, malheureusement toujours au stade beta. Nous nous contenterons donc des scores Xeon 32 bits, et Opteron 32 et 64 bits.
- HPLinpack
Avant de commencer, autant le dire tout de suite, la compilation de Linpack est extrêmement compliquée et nécessite de très bonnes connaissances dans l'environnement linux. Oubliez tout de suite le "./configure;make;make install" classique, ceci ne suffira pas. Il faut en effet créer un profil de compilation pour l'environnement dédié, installer de nombreuses librairies (BLAS, CBLAS, ...etc), compiler le tout dans le bon mode (-m64 pour x86-64, -m32 pour x86-32), puis exécuter le benchmark.
Pour faire plus simple vu la complexité de compilation, nous avons fait un backup du répertoire, que vous pourrez downloader ici.
Bien que linpack soit prévu à l'origine pour s'exécuter avec mpi sur un cluster, une solution mono-thread est possible. Voici les paramètres que nous avons utilisés pour ce benchmark :
| ============================================================================ HPLinpack 1.0a -- High-Performance Linpack benchmark -- January 20, 2004 Written by A. Petitet and R. Clint Whaley, Innovative Computing Labs., UTK ============================================================================ An explanation of the input/output
parameters follows: The following parameter values will be used: N : 2900 3000 ---------------------------------------------------------------------------- - The matrix A is randomly generated for
each test. |
En mode x86-64, on compile d'abord les librairies en mode x86-64, puis Linpack, également en mode x86-64. En mode 32 bits, on compile les librairies en 32 bits (flag -m32), puis Linpack en 32 bits. On obtient deux exécutables (qui se trouvent dans l'archive ci dessus) :
root@linux:~/review3264/root/hpl/bin#
file x86-32/xhpl root@linux:~/review3264/root/hpl/bin#
file x86-64/xhpl |
Les résultats obtenus par Linpack sont notés en GFlops, bien que, vu l'unique CPU, cette valeur soit à convertir en MFlops dans notre test. La valeur Ravg s'obtient en faisant une moyenne des valeurs obtenues pour NB = 1 et NB = 2 (vu le setup des tests), quant à la valeur obtenue pour Rpeak, c'est la valeur maximum obtenue. Voyons tout de suite les résultats :
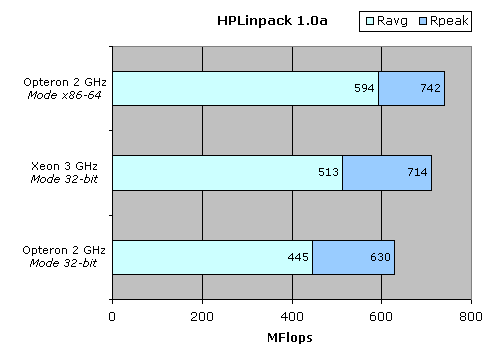
Première constatation, le Xeon 3 Ghz est environ 15% plus performant que l'Opteron en mode 32 bits. Ceci peut principalement s'expliquer par l'utilisation massive du SSE/SSE2 sur les calculs de matrice en lieu et place des calculs FPU. Le SSE étant conçu pour ce type de calcul, il semble logique que le Xeon s'en tire mieux. Toutefois, le mode 64-bit permet à l'Opteron de repasser en tête avec un gain de 16% sur le Xeon 3 Ghz en 32 bits. On constate ici l'intérêt du mode x86-64 puisque le gain, constaté sur l'Opteron, est d'environ 33%. Ce gain s'explique par le fait que le nombre de GPR étant plus élevés, les permutations sont beaucoup plus aisées et nécessitent moins d'accès au cache ou à la mémoire. Il aurait été intéressant de pouvoir obtenir des résultats sur le Xeon en mode x86-64, mais le compilateur n'a pas permis de construire une version fonctionnelle.
- Seti@Home
Logiciel bien connu depuis maintenant plusieurs années, le client Seti@Home présente comme principal intérêt l'utilisation massive du processeur pour des calculs scientifiques complexes. Adapté sur de nombreuses plates-formes, des version ia32 et x86-64 sont disponibles depuis longtemps sur le site officiel de Seti. Malheureusement, les auteurs du programme n'ont jamais daigné mettre les sources du programme a disposition.
Nous avons donc utilisé le binaire 3.08 pour "i686-pc-linux-gnu" pour la partie 32 bits et le binaire 3.08 "x86_64-pc-linux-gnu" pour la partie 64 bits. Vous pouvez télécharger ces deux executables ici. Bien sur, afin d'obtenir des résultats comparables, nous avons toujours utilisés la même WU (work unit), que vous pouvez télécharger ici. Le temps de traitement est calculé grace à un petit script :
| #!/bin/bash
date > bench_result.txt |
On fait ensuite la soustraction entre la date de début et la date de fin et l'on obtient le temps de traitement. Comme pour Linpack, ce binaire ne fonctionne pas sur Nocona en mode 64 bits, renvoyant le message "Illegal Instruction" dès le lancement. Voyons maintenant le résultat :
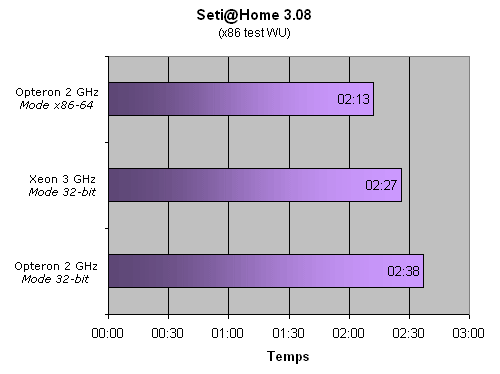
L'Opteron 2 GHz, en mode 32 bit, complète notre WU de test en 2 heures et 38 minutes alors que le Xeon Nocona, toujours en mode 32 bits, la termine en 2 heures et 27 minutes, soit un petit gain d'à peine plus de 5%. Lorsqu'on passe en mode x86-64 sur l'Opteron, c'est un gain de 15% par rapport à l'Opteron en mode 32 bits qu'on observe. Le passage de 32 à 64 bits permet à l'Opteron de terminer 10% devant le Xeon Nocona 3 GHz. Encore une fois, il est regrettable que nous n'ayons pu effectuer de test en 64 bits avec le Xeon sur ce benchmark. Toutefois, les tests suivants permettront de voir ce Xeon en mode EM64T.