
| Sommaire: |

Etude des caches :
Débits & Latences
Après avoir vu son fonctionnement, intéressons nous maintenant à ses performances par le biais de tests de latence et de débits :
1) Etude des débits
Les tests de débit consistent à mesurer le temps de lecture de buffers de taille croissante, de 1 Ko à plusieurs Mo. Les lectures s'effectuent en 32 bits (integer), 64 bits (MMX) et 128 bits (SSE), en utilisant pour chacun d'eux l'instruction de lecture la plus rapide. Les résultats nous fournissent de nombreuses informations sur le processeur, notamment sur les caches de données, les unités de chargement, et également sur le bus mémoire.
Afin de mettre en évidence les améliorations apportées au K8, nous avons comparé les résultats d'un Opteron 244 (cadencé à 1,8GHz) à ceux d'un Athlon XP de même fréquence, le 2200+. Regardons dans un premier temps le résultat obtenu en lecture 32 bits.

Voyons ce que l'on peut déduire de ces courbes.
- La forme générale de la courbe de l'Opteron met en évidence
son cache de données L1 de 64 Ko, ainsi que les 1024 Ko du cache
L2. Remarquons que la courbe s'étend jusqu'à 1088 Ko,
soit 1024 + 64. On voit donc là de façon concrète
la relation exclusive entre les caches, dont les tailles
s'additionnent. Il en est de même sur la courbe de l'Athlon XP,
dont les 64 Ko du L1 s'ajoutent aux 256 Ko du L2, portant ainsi la quantité
de cache à 320 Ko.
- L'Athlon XP offre un débit de 5,2 octets par cycle (10000 Mo/s)
et l'Opteron un débit de presque 7 octets par cycle (12500 Mo/s).
Le test 32 bits consiste à lire 4 octets par instruction, ce
qui signifie que le K8 est capable de traiter deux opérations
par cycle. Ceci est possible grâce à l'unité de
lecture/écriture (Load-Store Unit, ou LSU), qui est capable d'effectuer
deux opérations de lecture ou écriture 64 bits par cycle.
Pour alimenter la LSU, le cache L1 est, comme nous l'avons évoqué
plus haut, de type Dual Ported, ce qui veut dire qu'il
est également capable de supporter deux opérations de
lecture et/ou écriture 64 bits par cycle. A 1,8GHz, ceci confère
au couple LSU/L1 un débit maximal de 2 ops x 8 octets x 1800MHz
= 28800 Mo/s en 64 bits, ou encore 2 ops x 4 octets
x 1800MHz = 14400 Mo/s en 32 bits.
L'Athlon XP affiche un débit 10000 Mo/s, ce qui réprésente 70% du débit maximal théorique calculé plus haut. Avec un débit de 12500 Mo/s, l'Opteron affiche près de 87% du débit maximal théorique, et s'avère donc plus performant que l'Athlon XP. Ceci reflète les améliorations apportées dans le pipeline du K8, et notamment la meilleure répartition des instructions vers les unités de calcul. Le noyau du K8 exploite ainsi mieux les unités de calcul par rapport à l'Athlon XP, ce que révèle clairement ce test.
- Le cache L2 de l'Opteron offre un débit de 6530 Mo/s et celui de l'Athlon XP un débit de 5000 Mo/s. Le cache L2 de ces deux processeurs n'est pas dual-ported, ils ne peuvent donc traiter qu'une opération par cycle, ce qui nous donne un débit maximal théorique de 1 op x 4 octets x 1800MHz = 7200Mo/s. Le cache L2 de l'Opteron offre une valeur très proche de ce maximum théorique.
Voyons maintenant les résultats obtenus en 64 bits :
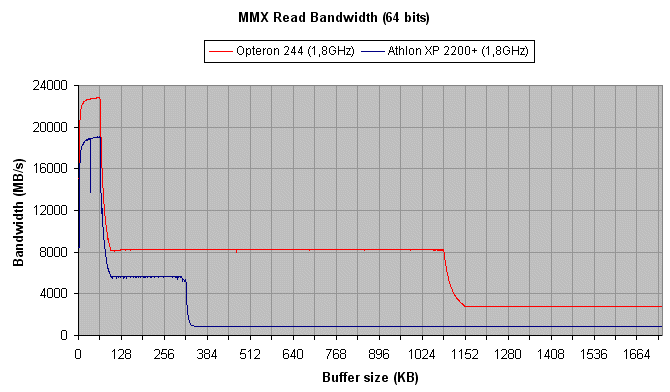
- Comme nous l'avons calculé plus haut, le cache L1 offre un
débit de 28800Mo/s en 64 bits. L'Athlon XP affiche 18800 Mo/s
(soit 65% du débit maximal théorique) et l'Opteron 22700Mo/s
(soit 79% du débit maximal). Ces résultats confirment
ceux obtenus en 32 bits.
- Le cache L2 de l'Opteron offre un débit de 8260 Mo/s et celui de l'Athlon XP un débit de 5700 Mo/s. Nous sommes loin du maximum théorique de 1 op x 8 octets x 1800MHz = 14400Mo/s. Les lectures 64 bits saturent le cache L2 des deux processeurs, et ceux-ci offrent le débit maximal qu'ils peuvent fournir. Par rapport aux transferts 32 bits, l'augmentation de debit est de 26% pour l'Opteron et de 14% pour l'Athlon XP. Cet écart s'explique par le bus L2 plus large de l'Opteron, ce qui lui permet d'offrir une bande passante plus élevée que celle de l'Athlon XP.
Regardons maintenant en mode 128 bits, obtenu en utilisant le jeu d'instructions
SSE.
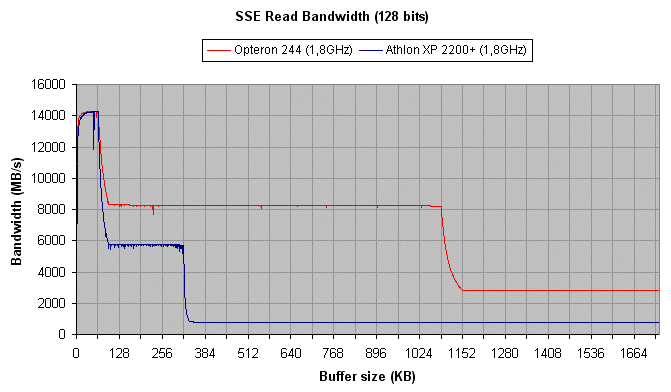
Le débit obtenu sur le cache L1 des deux processeurs est de l'ordre
de 14200Mo/s, ce qui est inférieur au mode 64 bits. Nous voyons
là une des limites de la LSU : si elle supporte deux opérations
64 bits par cycle, elle n'est en revanche capable d'effectuer qu'une seule
lecture 128 bits à la fois, et cette lecture nécessite deux
cycles ! Ce qui porte alors son débit théorique à
16x1800/2 = 14400Mo/s. Les deux processeurs offrent des débits
pratiques très proches de cette valeur, car la LSU joue alors le
rôle de facteur limitant.
Les résultats sur le L2 sont les mêmes que ceux obtenus en
64 bits, preuve que les caches saturent dès que les lectures sont
faites en 64 bits.
2) Etude des latences
Le temps de latence d'un cache est le temps, exprimé en cycles
processeurs, séparant une requête en lecture du moment où
la donnée requise est effectivement disponible. Elle permet de
donner une estimation de la vitesse de réaction d'un cache.
En effet une mémoire cache, comme toute mémoire, ne réagit
pas de façon instantanée. Dans la pratique, ce temps de
latence peut être en partie masqué par le flux des instructions
dans le pipeline, mais l'algorithme qui permet de le calculer correspond
au cas le pire, c'est-à-dire qu'on utilise la donnée juste
après la requête de lecture.
Regardons, à titre de rappel, les résultats obtenus sur un Athlon XP 2200+ :
2 cache levels detected |
La latence du L1 est conforme à ce qu'annonce AMD pour ce processeur,
à savoir 3 cycles. La latence du cache L2 est en revanche mesurée
à 17 cycles, alors qu'AMD annonce entre 8 et 11 cycles. La raison
de cette différence, et le constructeur s'en explique dans un document,
tient dans la pénalité due au Victim Buffer. En effet, l'algorithme
de mesure de la latence provoque un débordement constant du VB,
et le temps mesuré inclut la vidange du VB dans le cache L2, et
correspond donc au cas le pire en terme de performances. Ainsi, sur les
17 cycles mesurés, 8 cycles correspondent à la phase de
vidange du VB, ce qui porte la latence réelle du L2 à une
valeur de l'ordre de 9 cycles.
Voyons maintenant les résultats du même test mené sur un Opteron 244 :
2 cache levels detected |
La latence du cache L1 n'a pas changé par rapport au K7, en revanche
celle du L2 a perdu pas moins de 4 cycles. Si l'on applique le même
raisonnement en ce qui concerne le VB, on obtient une latence réelle
du cache L2 de 5 cycles. Mais difficile de dire si la phase de vidange
du VB n'a pas été elle-même améliorée.
Quoiqu'il en soit, et les tests précédents l'ont aussi démontré,
le cache L2 du K8 est globalement beaucoup plus performant que celui du
K7.
Ce test nous permet également de comparer les latences mesurées
depuis la mémoire, une fois passés les caches L2. L'Opteron
affiche 120 cycles, à comparer aux 360 cycles de l'Athlon XP (cadencé
à la même fréquence, ce qui donne des rapports en
temps absolu identiques). Cette différence s'explique bien entendu
par le contrôleur mémoire intégré du K8, qui
permet d'obtenir des latences mémoire près de trois fois
plus faibles que celles obtenues par une architecture classique avec contrôleur
externe.