
| Sommaire: |

Performances du K8 en 64 bits
Le plus difficile a certainement consisté à trouver le code le plus approprié à ce genre de tests. Nous avons essayé de nombreuses routines faisant intervenir des calculs entiers et des calculs flottants, et nous sommes tombés sur quelques constatations, dont il a fallu tenir compte pour donner toute la validité souhaitée aux tests que nous avons effectués.
- En comparaison à la version 6.0, la version 8.0
du compilateur de Microsoft semble apporter d'importantes optimisations
sur les calculs flottants. A partir d'un même code C utilisant
des flottants 32 et 64 bits (float et double), le code généré
par la version 8.0 s'est souvent montré beaucoup plus rapide
que celui généré par la version 6.0. Nous avons
donc choisi de ne garder que les résultats des compilateurs dans
leur version 8.0, pour les codes 32 bits et AMD64.
- Le compilateur pour AMD64 nous a posé pas mal de soucis. Le code généré est d'une fiabilité sans faille, mais il semblerait que certaines optimisations n'aient pas encore été finalisées. Ainsi par exemple, certaines fonctions ne sont que partiellement implémentées. Le compilateur ne fait pas appel aux instructions flottantes de trigonométrie (sinus, cosinus) mais aux fonctions de la librairie standard C, qui sont particulièrement lentes. De la même façon, l'utilisation de classes C++ a produit un code très lent, ce qui nous a obligé de recourir à du code C uniquement.
En résumé, autant de désagréments liés au caractère "béta" de ces compilateurs et qui ont rendu ce test assez délicat afin de ne pas fournir des résultats erronés. Nous espérons que la version définitive du compilateur AMD64 de Microsoft corrigera tous ces petits désagréments.
Nous avons donc retenu les routines suivantes :
- Filter : une routine de moyenne sur une série de tableaux de données.
- Rotozoom : une routine mixant la rotation et le zoom d'une image 512x512.
- Arithmetic : une routine effectuant des opérations arithmétiques entières : additions, multiplications, divisions, décalages, branchements.
- Whetstone : deux routines de calcul flottant identiques, mixant une série d'opérations flottantes classiques (additions, multiplications, divisions). Les deux routines différent par le type de nombre flottant manipulé : simple précision (float 32 bits) et double précision (double 64 bits).
Toutes ces routines ont été compilées au sein de
deux exécutables, une version 32 bits et une version AMD64. La
première constatation concerne la taille des deux fichiers binaires
: 33280 octets pour la version 32 bits, et 41472 octets pour la même
version AMD64. Le binaire 64 bits est donc 24% plus volumineux que son
homologue 32 bits. Pas de doute, la recompilation 64 bits fait bien grossir
le code !
Un index de performance de 100 a été attribué au
code 32 bits afin de permettre une meilleure visualisation des résultats
obtenus avec les deux versions. Voici donc ce qu'il en est avec les routines
de calcul entier :
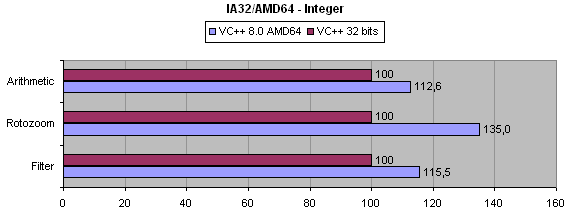
Avec un gain de près de 35%, la routine de rotozoom semble bénéficier
tout particulièrement de la recompilation 64 bits. Jetons un coup
d'oeil aux codes générés par les deux compilateurs
pour cette routine de rotozoom :
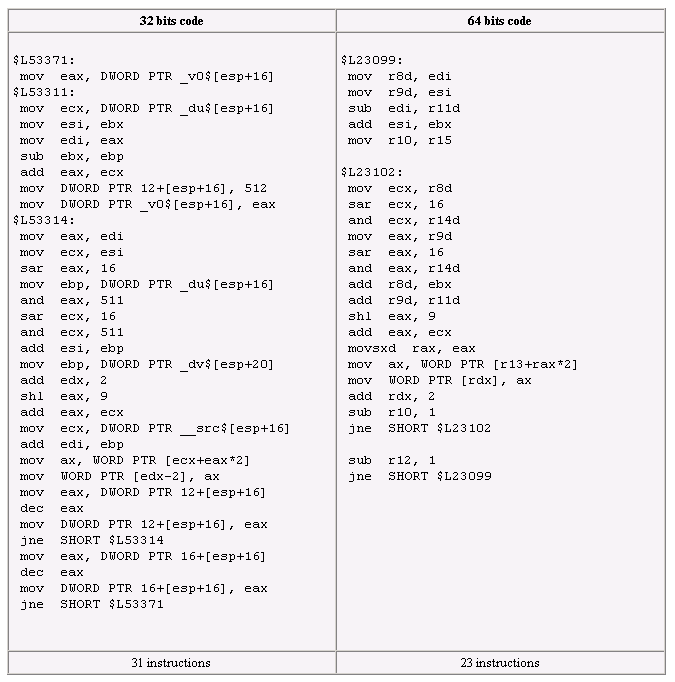
Le gain de performance en 64 bits est donc principalement du à la diminution du nombre d'instructions par rapport au code 32 bits. La routine utilisant de nombreuses variables, le compilateur 32 bits a besoin de nombreuses instructions pour les récupérer depuis la pile (à partir du registre [esp], ce qui rend ces instructions facilement identifiables). Ce qui n'est pas le cas dans le code 64 bits, où chaque variable ou constante se voit stockée dans un registre. Cela apparait clairement dans le code, où l'on remarque l'usage des 8 GPR supplémentaires, r8 à r15.
Comme nous le voyons, la diminution du nombre d'instructions apporte d'importants gains de performances. Mais un autre facteur peut intervenir, qui permet de gagner quelques cycles processeurs. Celui-ci apparaît dans la routine de calculs arithmétiques, dont nous n'afficherons qu'un extrait des codes générés :

Dans ce cas, le code 64 bits est également plus court que son équivalent
32 bits. Mais le plus remarquable concerne une instruction en particulier
utilisée par le compilateur 64 bits : cmovg, à
la 10ème ligne.
Cette instruction, qui existe depuis le Pentium Pro, est un mov conditionnel
(conditionnal move if greater), et permet d'éviter un branchement.
Pour la petite histoire, Intel a doté le Pentium Pro de cette instruction
afin de l'armer face à de trop nombreux branchements, nuisible
à son pipeline deux fois plus long que celui du Pentium.
Le compilateur 32 bits n'a pas utilisé cette instruction et a
donc généré un branchement (jle SHORT $L22360). Pourquoi
cela ?
La raison est simple : le compilateur 32 bits génère du
code IA32, et qui doit donc tourner sur tout processeur conforme à
cette architecture ; cela inclut les processeurs antérieurs au
Pentium Pro, qui ne supportent pas cette instruction spécifique.
Il est bien entendu possible de changer les options du compilateur afin
qu'il utilise les instructions d'une génération supérieure
au 386 (nous avons pour notre part laissé les réglages par
défaut), mais cela n'est en général pas conseillé
car le code ainsi généré ne pourrait être pas
réellement qualifié de code IA32.
Le compilateur 64 bits en revanche génère du code pour une architecture débutant avec l'Athlon 64, et peut donc générer toutes les instructions que celui-ci supporte, en l'occurrence le cmovg dans notre exemple.
Voyons maintenant les résultats obtenus avec les deux routines en virgule flottante.
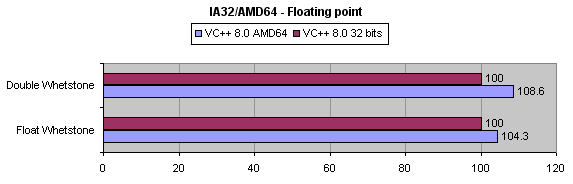
Les gains sont bien moins importants qu'en calcul entier, et plafonnent
à un peu plus de 8% pour la routine utilisant des flottants double
précision. Regardons un extrait des codes générés
:
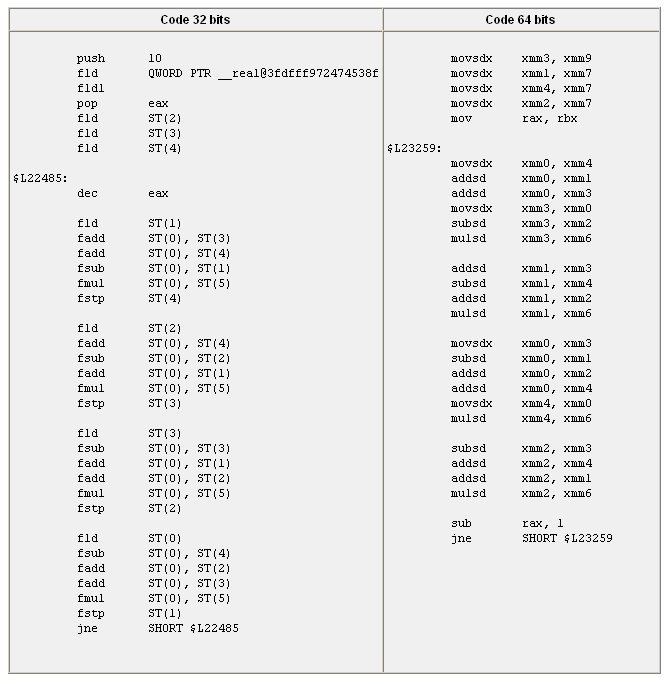
Le code généré par le compilateur 32 bits est du
code x87 particulièrement optimisé, ce qui, comme nous l'avons
évoqué, semble être un ajout récent de la version
8.0 du compilateur de Microsoft. Les registres flottants sont utilisés
de façon optimale, et ce code est d'une grande efficacité.
Cette même routine a été traduite par le compilateur
AMD64 en instructions scalaires SSE/SSE2 (le suffixe "sd" à
la fin de chaque instruction signifie "scalar double"). Comme
on peut le voir, le nombre d'instructions générées
est à peu près identique, légèrement supérieur
en code x87 à cause de la gestion des registres par la pile. Les
fonctions de notre test étant relativement simples, le compilateur
64 bits n'a que très peu utilisé le surplus de registres
SSE disponibles, et on remarque d'ailleurs que le code x87 ne travaille
qu'avec les registres lui aussi.
Cela dit, nous voilà rassurés quant au comportement du K8 en code SSE/SSE2. A condition d'utiliser des instructions scalaires, le K8 ne perdra pas sa suprématie en calcul flottant.
Seule ombre au tableau : les fonctions trigonométriques. Comme nous l'avons évoqué plus haut, le compilateur 32 bits utilise les instructions x87 pour générer un sinus, un cosinus ou un tangente, là où la version 64 bits utilise les fonctions standards de la librairie C, qui ne propose qu'une approximation des fonctions trigonométriques à l'aide de suites (donc très lente). Espérons que la version définitive du compilateur de Microsoft adoptera une méthode plus rapide.
En conclusion
Les résultats obtenus après recompilation 64 bits nous ont agréablement surpris, et on est en droit d'espérer que les valeurs que nous avons obtenues soient généralisables. La condition étant bien sûr d'avoir à disposition un compilateur efficace, et celui de Microsoft est prometteur. Si la version définitive corrige les quelques problèmes d'optimisation que nous avons rencontrés, le nouveau Visual C++ 8.0 risque de devenir rapidement une référence dans les compilateurs utilisés par l'industrie, notamment celle du jeu vidéo, comme c'est le cas aujourd'hui pour la version 6.0.
Comme vous l'avez compris, la sortie d'un bon compilateur AMD64 sera
le facteur déclenchant de l'apparition de drivers matériels
et d'API performantes destinées à l'AMD64, qui elles-mêmes
rendront les environnements 64 bits attractifs aux utilisateurs.