
| Sommaire: |

Le SSE3 détaillé
Introduit avec le Pentium III, le SSE avait apporté 50 nouvelles instructions couvrant un peu tout les domaines et surtout, la possibilité de travailler avec des registres 128 bits en plus des classiques registres MMX amenés avec le Pentium. Toujours conforme au schéma SIMD (une instructions, plusieurs données), le SSE a évolué ensuite avec le Pentium 4 par le biais de la norme SSE2 et de ses 144 nouvelles instructions. Dans le Prescott, ce ne sont pas 144 ou 50, mais seulement 13 nouvelles instructions qui apparaissent. Parmis elles, les developpeurs auront enfin droit aux opérations de calcul horizontal, comme nous le verrons un peu plus loin. On peut créer trois groupes avec ces nouvelles instructions, que voici :
- FISTTP (Conversion d'un flottant vers un entier)
- ADDSUBPD / ADDSUBPS (Addition en calcul vertical)
- MOVDDUP / MOVSHDUP / MOVSLDUP (Duplication)
- LDDQU (Chargement de données non-alignées sur 128 bits)
- HADDPD / HADDPS / HSUBPD / HSUBPS (Addition / soustraction horizontale)
- MONITOR / MWAIT (Controleur des threads pour l'HT)
Voici donc, en plus, détaillé, le fonctionnement et l'utilité de ces nouvelles instructions. Bien entendu, il faudra attendre qu'un compilateur supportant le SSE3 soit disponible avant de pouvoir s'attendre à un gain.
- Instruction FISTTP
Au commencement était l'instruction FISTP. Cette instruction permet de convertir un nombre flottant (donc avec des virgules) en nombre entier (donc sans virgule). Tout irait pour le mieux dans le meilleur des mondes si une seule méthode d'arrondi existait. Or, il en existe deux principales : "Chop" et "Even". La première, "chop" est un arrondi simple puisqu'il se contente de supprimer la partie flottante. Ainsi, l'arrondi de 5.99 en mode "Chop" est 5. Le mode "Even" est plus précis puisqu'il ajoute 0.5 à la valeur et coupe ensuite la partie flottante. Ainsi, pour 5.99, on obtient alors 6.49, soit 6 une fois arrondi. Vous l'aurez compris, le mode "Even" crée moins d'erreur que le mode "Chop" et c'est donc celui-ci qui est utilisé par défaut. Lorsqu'une instruction FISTP arrive, c'est l'état du FCW (Floating Point Control Word) qui défini le type d'arrondi à utiliser. Or, par défaut, celui-ci est positionné sur "Even" puisque c'est le mode d'arrondi qui crée le moins d'erreur.
Malheureusement, dans le cas ou le programmeur voudrait utiliser le mode
"Chop", il est obligé de sauvegarder l'état de
FCW, de le modifier vers le mode "Chop", d'exécuter l'instruction
FISTP, puis de remettre FCW a son état premier. Or, la modification
de FCW est relativement lente et donc fait perdre du temps. C'est la qu'intervient
l'instruction SSE3 "FISTTP". Celle-ci ne vérifie par
l'état de FCW et force l'utilisation par défaut de "Chop".
Les programmes utilisant ce type d'arrondi pour certaines opérations
gagneront donc en cycle avec cet instructions. Voyons un bout de code
:

Comme on le voit, dans le cas d'une conversion x87 -> INT en "even", on continue d'utiliser FISTP, mais on peut maintenant utiliser FISTTP pour les conversions en mode "chop".
- Instruction ADDSUBPD / ADDSUBPS
Les instructions ADDSUBPD et ADDSUBPS permettent d'effectuer simultanement une addition et une soustraction sur deux registres 128 bits. La fonction ADDSUBPD utilise des mots doubles (64 bits) et divise le registre en deux alors que la fonction ADDSUBPS utilise des mots simples (32 bits) et divise le registre en quatre. Voyons un schéma :
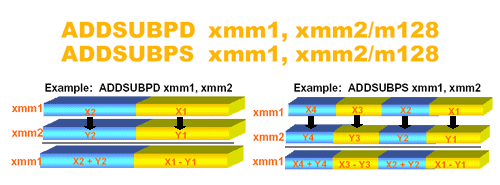
Ces deux nouvelles instructions evitent donc de faire une opération d'addition et une opération de soustraction avec des shifts pour acceder aux bits necessaires. Grace à celle-ci les deux opérations sont faites grace à la même instructions. Ce type d'opérations est trés utilisées dans les transformation de Fourier (FFT).
- Instruction MOVDDUP / MOVSHDUP / MOVSLDUP
Complémentaire des instructions ci-dessus, les instructions MOVDDUP / MOVSHDUP / MOVSLDUP servent à faire un déplacement avec copie. Existant également en Double (MOVDDUP) et en Simple (MOVSHDUP / MOVSLDUP) précision, ces instructions executent un MOV et un décalage et une copie dans la même instruction :
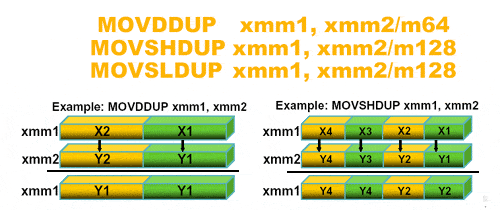
L'utilité de cette fonction est encore une fois de faire en une fois ce qu'on fesait avant en plusieurs. Le nombre de cycle gagné permet donc d'effectuer cette opération dans un tems plus court.
- Instruction LDDQU
L'instruction LDDQU signifie "LoaD Double Qword Unaligned". Pas franchement nouvelle, cette instruction permet de faire la même chose que MOVDQU, mais plus vite. Le but est ici de charger 128-bits de donnée non-aligné. Via une meilleure gestion interne des caches, il permet de gagner environ 30% de rapidité face au MOVDQU classique. Quasi-exclusivement destinée à l'encodage vidéo, Intel annonce un gain d'environ 10% sur les taches de compression MPEG4. Il faudra comme toujours attendre l'arrivée des logiciels optimisés SSE3 pour se rendre compte du gain. Ceci dit, dans le cas de cette instruction, elle ne devrait pas demander un travail énorme aux développeurs.
- Instruction HADDPD / HADDPS / HSUBPD / HSUBPS
On les attendait depuis un moment, elles sont là. Disponible chez AMD depuis le 3DNow!, les opérations d'addition et de soustraction horizontale sont donc maintenant disponibles dans le SSE3. On pourra donc effectuer une opération mathématique en utilisant deux données prises dans un même registre (2x64 ou 4x32 dans un registre de 128 bits SSE). Actuellement, il est possible de faire des opération d'additions horizontales (HADD) et de soustractions horizontales (HSUB) sur des mots de précision simple (PS - 32 bits) ou de précision double (PD - 64 bits). Voyons le schéma :
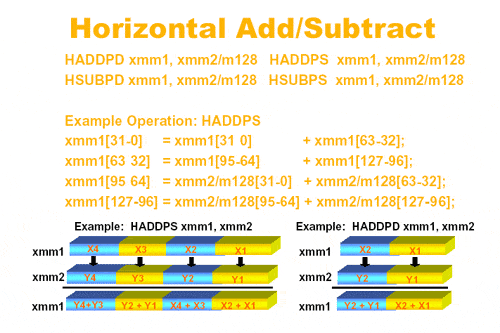
Principalement utile dans les calculs graphiques 3D ou les produits scalaires sont trés utilisés, ces quatres instructions sont probablement les plus attendues. Nous verrons dans les mois à venir
- Instruction MONITOR / MWAIT
Il s'agit cette fois d'instruction uniquement destinée à gerer au mieux l'Hyper-Threading. En fait, le but est de synchroniser les deux threads utilisés de la meilleure facon possible afin qu'ils exploitent l'HT de la facon la plus équilibrée possible. Au final, de meilleurs résultats via une exploitation plus précise de cette fonctionnalité sont attendues. Intel fournis un exemple :

Il faut donc synchroniser les threads. Bien sur, pour tirer parti de ces nouvelles fonctionnalités SSE3, il faudra recompiler les programmes et ajouter ces nouvelles instructions...