
| Sommaire: |

Prescott : Pipeline
et Caches
Jusqu'ici, tout va pour le mieux dans le meilleur des mondes pour le Prescott. Doté de nombreuses améliorations architecturelles face au Northwood, équipé d'instructions supplementaires, d'un cache deux fois plus importants et d'une finesse de gravure inférieure, le Prescott semble avoir tout pour plaire. C'est sur cette partie que le ciel va commencer à s'assombrir pour le dernier né de la gamme Pentium 4. Nous allons, par le biais de plusieurs tests, mettre en avant certaines caractéristiques du Prescott.
- Prescott et caches : constatations
Comme nous l'avons vu, le cache L2 du prescott est un cache de 1 Mo en 8-way associative. Outre sa taille double, il semble différer peu dans son architecture de celui du Northwood. Concernant le cache L1 Data, celui-ci passe de 8 Ko en 4-way à 16 Ko en 8-way. Nous avons tout d'abord testé la latence de ce cache pour voir si Intel avait modifié cet aspect primordial du fonctionnement de son architecture. Pour rappel voici l'état du cache d'un Northwood classique :
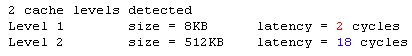
Le cache L1 du Pentium 4 Northwood est donc de 8 Ko et dispose d'une latence de 2 cycles, ce qui est très court et indispensable pour garantir un bon fonctionnement du pipeline. Pour ce qui est du niveau 2, la latence est de 18 cycles, ce qui fait 16 cycles pour ce niveau uniquement. La grosse surprise qui nous attends maintenant concerne les latences du Prescott :
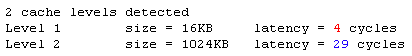
Ouch ! Une latence de 4 cycles sur le L1 et 25 cycles sur le L2 au lieu de 2 et 16 !! C'est absolument énorme et ralenti le cache d'une manière relativement effroyable. Nous avons ensuite effectué plusieurs tests de bande passante. Tout d'abord, un test avec cachemem qui a effectué des opérations de lecture / écriture et copie.
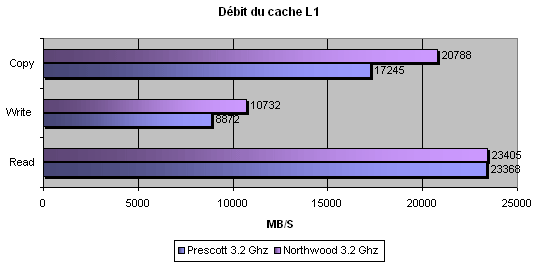 :
:
Outre la latence énorme du L1, le débit n'est pas non plus excellent puisque le cache L1 de 16 Ko du Prescott est plus lent que celui du Northwood. Si la lecture ne s'en ressent pas particulièrement, ce n'est pas le cas pour l'écriture ou la copie qui sont quasiment 20% plus lentes. Voyons maintenant ce qu'il en est du L2 :
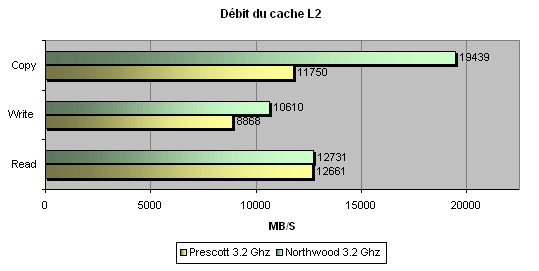
De même, si la lecture ne souffre pas spécialement du problème, l'écriture est ici aussi plus lente de 18%, quand à la copie, on constate que les débits sont 60% inférieurs au Northwood ! Bref, le cache du Prescott est clairement extrêmement lent par rapport à celui du Northwood. Après avoir tenté de trouver une raison à ce choix, nous en sommes venus à la conclusion que la seule chose qui puisse justifier ce choix était la montée en fréquence, et rien d'autres. L'allongement de la taille du pipeline à probablement également contribué à l'apparition de ces latences, mais force est de constate que ce qui faisait la forme du Pentium 4, sa latence faible, est maintenant fortement compromise.
- Pipeline et caches VS lenteurs : A qui la faute ?
Bien que beaucoup rejetterons la faute des lenteurs du Prescott sur son pipeline, nous avons voulu confirmer tout ceci par le test. C'est pourquoi, en consertation avec l'équipe d'Onversity, nous avons pensé à une série de test visant à mettre en avant tel ou tel responsable des lenteurs observées. L'idée à donc été de créer plusieurs tests basé sur des fonctions mathématiques destinées à un projet d'onversity de créer une librairie de grand nombres et de calcul de PI, a des fins pédagogiques. Le premier test fût réalisé sur des tables de 4 Mo, afin que celle-ci ne puissent pas tenir dans les mémoires caches et être ainsi moins dépendantes de celles-ci.
- Test avec tables de 4Mo : La faute au pipeline ?
Les opérations principales réalisée pour ce test sont au nombre de trois :
- Une addition sans condition de branchement (CB) : Le but est ici de tester la rapidité du pipeline. Puisqu'il n'y a pas de condition de branchement et le pipeline du Prescott ne devrait pas ici jouer énormément. Le code utilisé pour cette addition est très simple :

Voyons maintenant le résultat :
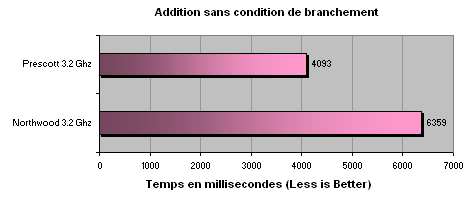
Comme on le voit ici, le Prescott boucle les opérations
bien plus rapidement que le Northwood. le gain est d'ailleurs de 55% !
Ceci est probablement a mettre sur le compte des améliorations
du pre-fetcher. Ceci dit, tout ceci est toutefois relativement logique
puisque que comme aucun branchement n'existe, le pipeline traite toutes
ces opérations à la suite sans être interrompu par
un branchement inopportun.
- Une addition avec condition de branchement (CB) sans retenue
: Ceci est donc dépendant du pipeline et relativement
indépendant du cache vu que la taille des tables est trop importante
pour y tenir. La condition de branchement va provoquer une mise à
l'épreuve du branch predictor, qui sera toutefois en mesure de
prédire correctement la prochaine branche, et nous verrons l'influence
du pipeline sur ces opérations.
- Une addition avec condition de branchement (CB) et avec retenue aléatoire : Encore pire à traiter pour l'unité de prédiction de branchement, c'est cette fois une addition avec condition de branchement ET retenue aléatoire qui va être executée. La branch predictor sera dans la majorité des cas incapable de prédire l'état de la branche. L'influence du pipeline va donc ici être mise encore plus en avant.
Ces deux fonctions sont créée via le code ci-dessous :

Dans le cas de la retenue aléatoire, les valeurs val1 et val2 sont générées aléatoirement :

Voyons maintenant les résultats obtenus :
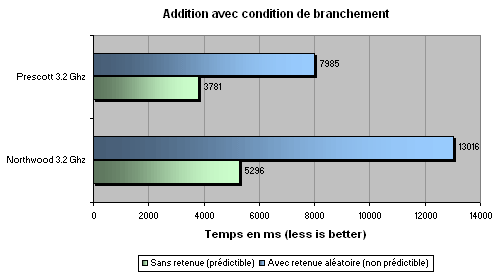
Encore une fois, et malgré les branchements aléatoires, le Prescott reste largement en tête face au Northwood. Le résultat des améliorations est ici largement visible puisque les résultats s'améliorent de 40% et 60%. D'ou vient donc les mauvaises performances du Prescott ? Visiblement pas du pipeline comme on a pu le lire ça et là. Voyons maintenant le cache...
- Test avec tables de 40 Ko : La faute au cache !
Les tables de 40 Ko rentrent sans problème dans le cache L2. Nous allons donc reprendre les tests présentent, mais avec ces tables beaucoup plus petites. Celle-ci mettrons en évidence l'influence du cache sur les performances de ces instructions. Pour commencer, reprenons l'opération d'addition simple sans conditions de branchement :
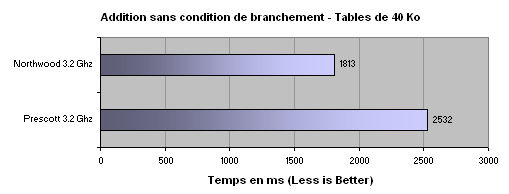
Alors que le prescott dominait avec les tables de 4 Mo, il est ici écrasé par le Northwood en terme de performance et passe de 55% plus rapide à 40% plus lent ! La seule chose qui diffère ici est l'emplacement des données, preuve de l'extrême lenteur du cache du Prescott qui grève les performances de manière impressionnante. Terminons avec un test incluant des conditions de branchement aléatoire et non-aléatoire afin de voir comment régit le cache L2 avec beaucoup d'accès :
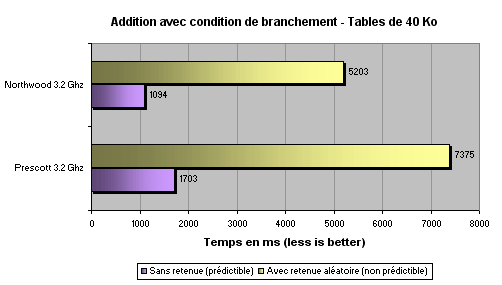
Respectivement 40% et 55% plus lent que le Northwood sur ces opérations, le Prescott n'est ici clairement pas à la fête. Encore une fois, c'est la lenteur de son cache ainsi que son énorme latence qui grève les performances à ce point. Et il parait clair que pour compenser un cache si lent, Intel a vraiment du faire preuve d'ingéniosité dans l'optimisation de la micro-architecture.
Conclusion : Les lenteurs du Prescott viennent du cache et de sa latence énorme et non du pipeline comme on aurait pu le croire....