Benchmarks de l'architecture Atom
Après la théorie, passons à la pratique. Nous allons donc tester l'architecture Atom afin de mieux comprendre son fonctionnement. Nous testerons d'abord le moteur d'exécution, puis les caches avant de nous intéresser à l’Hyper-Threading et à la gestion du 64 bit. Bien sur, lors de ces tests, nous analyserons les choix faits par Intel pour ce nouveau processeur tout en comparant Atom avec les générations précédentes. Pour cela, nous avons choisi de confronter le core Diamondville aux architectures Northwood (Pentium 4), Dothan (Pentium M) et Conroe (Core 2). Commençons par mesurer les débits de différentes instructions x86 sur ces cœurs :
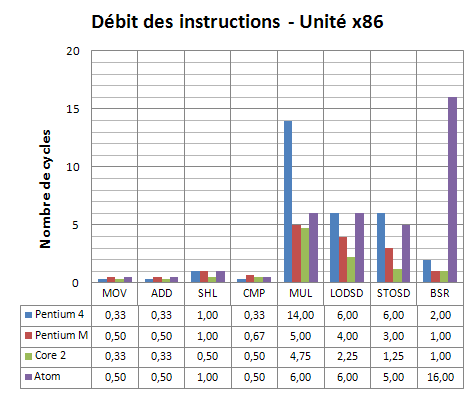
En analysant les résultats obtenus, nous avons pu détecter certains points intéressants. Tout d’abord, le cœur Atom comporte deux schedulers, un lent et un rapide. Le premier semble ne pouvoir travailler que sur 32 bits et offre un débit très correct sur les instructions x86 basiques comme les MOV, ADD, SHL et autres CMP, par rapport aux architectures modernes. Par contre, dès que l’instruction à traiter est plus complexe, elle emprunte le chemin « lent » qui se traduit par un temps d’exécution nettement plus important. Lors de ces mesures, nous avons remarqué une bizarrerie : aucune instruction n’est traitée en 3 ou 4 cycles. Soit le débit est de 2 cycles (ou moins) lorsque les instructions passent par le scheduler rapide, soit de 5 cycles au minimum si elles empruntent le scheduler lent. En conséquence, certaines instructions qui prenaient un peu plus de deux cycles sur les précédents processeurs Intel sont traitées en 5 cycles par le cœur Atom.
Intel a donc maintenu l’exécution rapide des instructions très utilisés au prix d’un ralentissement des opérations moins fréquentes. Et même plus. Car nous avons aussi remarqué que certaines instructions x86 legacy rarement utilisées ne sont même plus décodées directement. C’est par exemple le cas de l’instruction BSR (Bit Scan Reverse) ou de l’instruction AAA (ASCII Adjust for Addition). Tous les processeurs modernes exécutaient ces instructions en 1 cycle. Sur Atom, il en faut au moins 16 !
Passons maintenant au comportement du coeur Silverthorne avec des instructions x87 (FPU) :
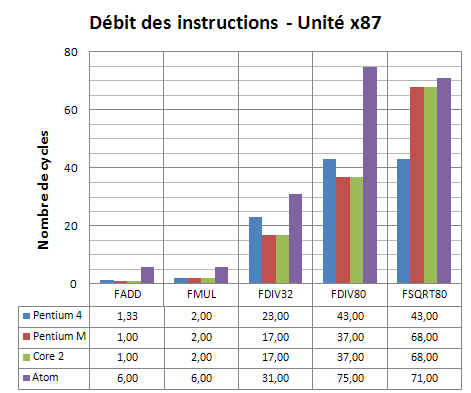
FPU = Instructions complexes = Scheduler Lent = 5 cycles minimum. Et comme on le constate, les instructions x87 ne sont pas le fort du cœur Atom. Non seulement il lui faut 6 cycles pour exécuter un simple FADD (une addition flottante) alors que le Pentium M réalisait la même opération en un seul cycle, mais visiblement, les divisions ne sont pas pipelinée. Il lui faut ainsi 75 cycles pour effectuer une division en 80 bits (pleine précision), soit deux fois plus que sur les architectures plus anciennes.
Poursuivons avec les instructions SIMD (MMX, SSE, …etc.) :
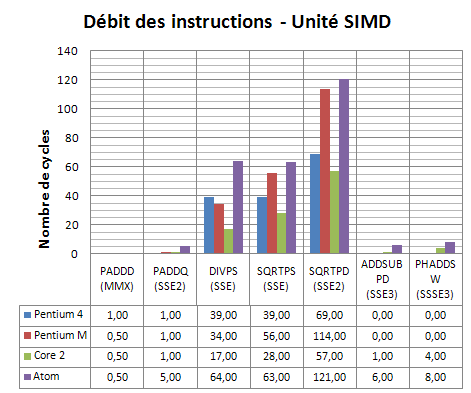
Le pipeline FP/SIMD contient une unité ADD 64 bit dédiée. Lorsqu’elle est utilisée, on obtient de très bonne performance avec le débit maximum de 2 instructions par cycle. C’est le cas par exemple de l’instruction MMX « PADDD », comme on le voit sur le graphe. Pour le reste, les choses se corsent puisque tout le traitement SIMD est effectué par l’unité complexe, ce qui implique, là aussi, un débit minimum de 5 cycles par instructions. Ainsi, la même addition, cette fois en 128 bits (PADDQ) passe de 1 cycle sur Pentium M à 5 cycles sur Atom. Même chose pour les instructions SSE3 et SSSE3 dont le débit chute de manière très net par rapport à un Core 2. Les divisions et autres racines carrées, quant à elles, souffrent aussi d’un timing plus important, même si la complexité de ce type d’opération réduit un peu l’impact pratique.
Passons maintenant aux caches. Pour mieux comprendre leur fonctionnement, nous avons mesuré la latence et le débit des caches L1 et L2 :
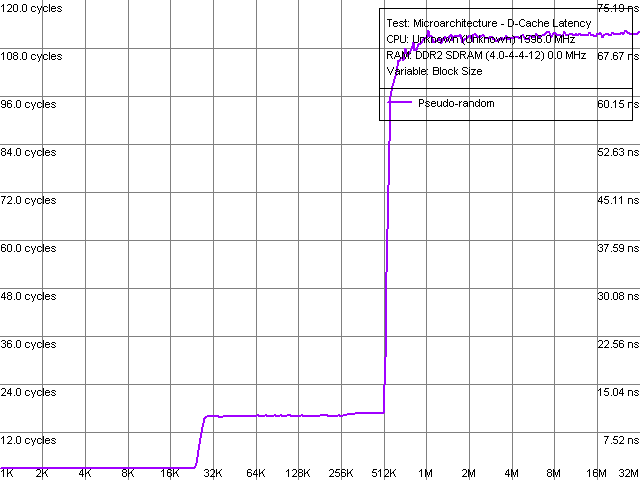 |
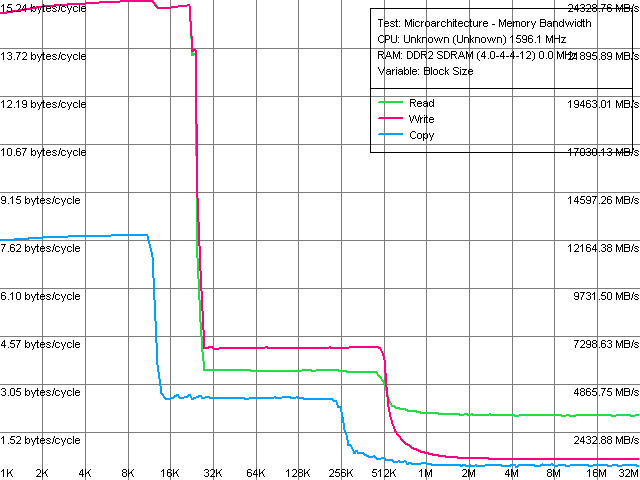 |
Le cache L1 de 24 Ko a une latence vue de l'extérieur de 3 cycles avec un débit à 1.6 GHz d’un peu plus de 24 Go/s. Côté L2, on observe un cache de 512 Ko doté d’une latence de 16 cycles et de lignes de cache de 128 octets. Son débit atteint environ 7 Go/s sur notre plateforme de test. Ces valeurs semblent normales, même si la latence du cache L2 est légèrement supérieure à celle que l’on pouvait trouver sur Core 2 (14 cycles). Visiblement, Intel n’a pas trop sacrifié les caches dans l’architecture Atom. Quoi de plus normal puisque ceux-ci sont cruciaux dans le fonctionnement d’un pipeline In Order.
Nous nous sommes ensuite intéressés aux deux fonctionnalités principales qu’Intel a choisi d’intégrer dans ce nouveau CPU : l’Hyper Threading et l’EM64T. Pour l’HT, l’utilité coule de source : vu l’architecture interne de ce core, il est très important d’utiliser au mieux le pipeline qui, non seulement est In Order, mais en plus est profond de 16 étages. Pour cela, l’une des solutions les plus logiques pour éliminer le maximum de « bulles » dans le pipeline est d’utiliser le multithreading par l’intermédiaire de l’HT. Toutefois, vu que l’activation de cette technologie entraine une hausse de la consommation électrique de 10%, il fallait vraiment que son efficacité soit démontrée. Nous avons donc comparé les gains obtenus en activant l’Hyper Threading sur un processeur Atom et sur un Pentium 4. Les résultats sont impressionnants :
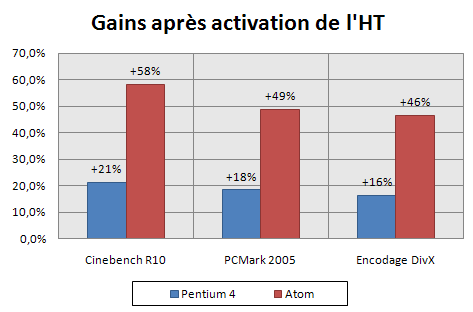
Lorsque l’Hyper Threading (SMT) est apparu avec le Pentium 4, il permettait d’obtenir des gains maximum de 20%. A l’époque, la présence de SMT s’expliquait par la longueur considérable du pipeline du P4 et par le besoin d’optimiser au maximum son rendement. Sur Atom, l’objectif est le même et les gains sont démultipliés. Sous Cinebench, le gain atteins quasiment 60% et , même dans les applications basiques simulées par PCMark 2005, on approche les 50%. On comprend donc aisément pourquoi Intel a choisi de sacrifier les 10% de consommation électrique nécessaires pour activer l’HT. Bref, pour peu que le système d’exploitation et les applications utilisées sur la plateforme Atom soient capables d’exploiter le SMT, on obtiendra un gain de performances très important.
Terminons en mesurant l’intérêt du x86-64 sur Atom. A première vue, la présence de l’EM64T sur cette plateforme peut paraitre superflue : celle-ci n’est pas destinée à supporter plus de 4 Go de RAM. Par contre, les registres généraux supplémentaires disponibles en mode 64 bit peuvent apporter un gain de performances. Comme pour l’HT, nous avons effectué une comparaison des gains entre P4 et Atom. Toutefois, les benchmarks 64 bits étant encore limités, nous avons du nous restreindre à Cinebench (encore lui) ainsi qu’au bon vieux Linpack :
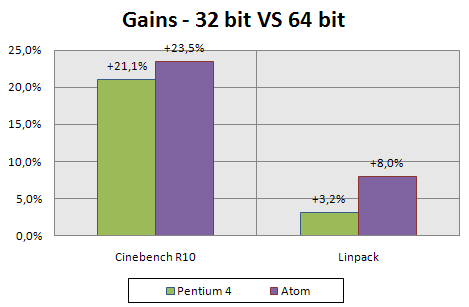
Si les gains sont bien présents et même supérieurs à ceux qu’on pouvait obtenir avec un Pentium 4, il ne faut pas perdre de vue que le passage en 64 bits pénalise l’efficacité des caches et augmente la mémoire utilisée. Or, la plateforme Atom est censée fonctionner avec une mémoire vive relativement limitée et nécessite impérativement des caches optimisés pour offrir des performances correctes. Dans ces circonstances, l’activation de l’EM64T par Intel dans le cœur Atom reste un mystère.