Nehalem : l'architecture en détail
Sur cette page, nous mettrons de côté toutes les fonctionnalités « Uncore » pour nous intéresser uniquement aux cœurs. Pour les Core i7, Intel a choisi d’optimiser au maximum l’architecture introduite avec les derniers Core 2 « Penryn » sans toutefois la bouleverser radicalement. Le but : augmenter au maximum l’efficacité des unités d’exécutions en organisant mieux les instructions et en accélérant la récupération des données par le biais des mémoires caches. Ainsi, on constate très vite que les unités d’exécutions de Nehalem sont quasi-identiques à celles déjà présentes sur les anciens Core 2. Au contraire, la majorité des améliorations touchent le front-end, c'est-à-dire les étapes chargées de la récupération (fetch) et du décodage (decode) des instructions.
- Front-End
Tout ceci est très compliqué et pour améliorer la compréhension de l’architecture, nous avons commenté grossièrement (chez Canard PC, on aime être grossier) le schéma classique fourni par Intel :
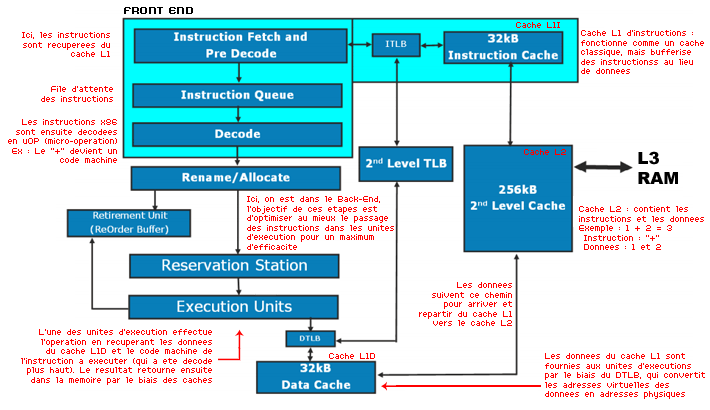
Le Front end est donc un élément primordial pour augmenter le débit des instructions et « nourrir » au mieux les unités d’exécutions. Pour cela, Intel a apporté trois améliorations principales au Front-End de Nehalem.
 |
La première concerne la prédiction de branchement. Petit rappel : dans les processeurs modernes, certaines unités sont chargées de prédire à l’avance le résultat de certains sauts (instruction du style : si A = 2 alors saute à tel adresse mémoire, sinon, à telle autre) afin de précharger les données situées après le saut et ce, AVANT que celui-ci n’ait été traité par les unités d’exécutions. Sur Nehalem, Intel a amélioré les prédictions de branchement sur l’instruction x86 « RET », très utilisée, qui sert à sortir d’une fonction pour revenir à la précédente, et a doté le mécanisme de prédiction du L2 d’un nouvel algorithme plus efficace sur les codes très larges. Ceci est principalement destiné aux applications serveurs qui utilisent de grosses bases de données. |
La seconde amélioration provient des macrofusions, un procédé déjà largement répandu dans les Core 2. Explications : comme nous l’avons vu sur le schéma ci-dessus, l’unité de décodage est conçue pour convertir une instruction x86 en micro-instructions (µop) traitable par les unités d’exécutions. Par exemple, une instruction x86 complexe comme une racine carrée est décodée en plusieurs µops. Mais l’inverse est aussi possible ! Par exemple, deux instructions x86 simples peuvent être transformées en une seule et même µop, ce qui permet de la traiter en un seul cycle d’horloge. Les Core 2 supportaient déjà la fusion de deux instructions de type CMP (compare) et JMP (saut), ce qui, dans la pratique, permettait de décoder, par exemple « si tel registre est égal à tel autre, alors saute à tel adresse » en une seule µop. |
 |
| Sur Nehalem, Intel a étendu les macro-fusions aux opérateurs < (inférieurs) et > (supérieur) dans les comparaisons, suivi d’un saut conditionnel. Pour reprendre notre exemple ci-dessus, un code effectuant « si tel registre est inférieur à tel autre, alors saute à tel adresse » sera lui aussi décodé en une seul µop. De plus, les macro-fusions ne fonctionnaient sur Core 2 qu’en mode 32 bits. Désormais, les Core i7 pourront aussi fusionner ces instructions en mode 64 bits. | |
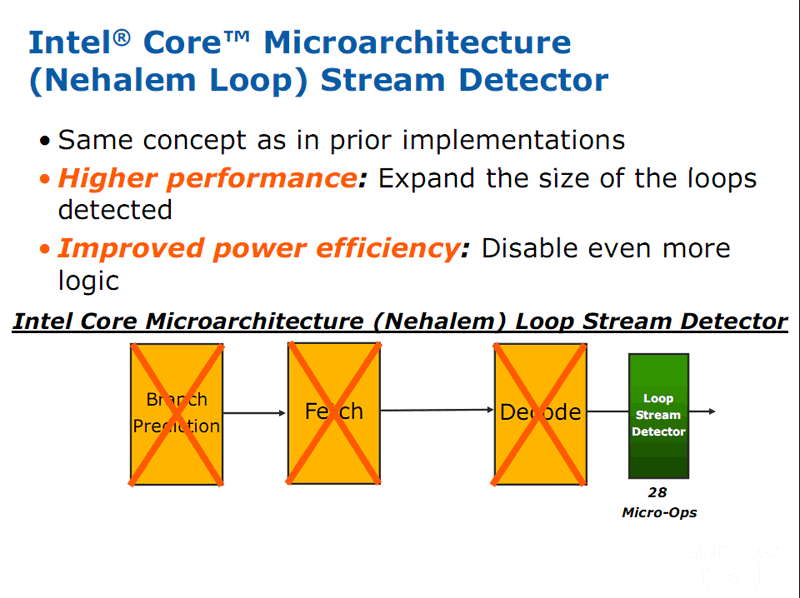 |
La dernière amélioration provient d’un autre procédé, lui aussi présent sur Core 2, conçu pour améliorer l’efficacité : le détecteur de boucle. Prenons le cas d’une boucle ou les mêmes opérations sont répétées plusieurs dizaines, centaines ou milliers de fois. Sur Core 2, la boucle était détectée en hardware et le front-end supprimait les étapes de prédictions de branchement et de récupération des instructions (fetch) à chaque « tour » dans la boucle. Des opérations inutiles puisque le principe même d’une boucle est d’utiliser les mêmes instructions. Sur Nehalem, le détecteur de boucle va encore plus loin puisqu’il est désormais placé après la dernière étape du front-end, c'est-à-dire le décodage des instructions x86 en µops. |
| En conséquence, lorsqu’une boucle est détectée, les instructions qu’elle utilise ne sont plus ni récupérées du cache, ni prédites ni décodées. Ceci amène un gain en performances et en consommation d’énergie puisque les unités de décodages sont moins sollicitées. | |
- Back-End
Voici donc pour le front-end. Comme nous l’avons vu, celui-ci est constitué de déclinaisons améliorées des mécanismes d’optimisation déjà mis en place dans le Core 2. Avant de passer aux unités d’exécutions, parlons du moteur OOO (Out-Of-Order) qui permet d’exécuter dans le désordre les instructions qui arrivent du front-end afin de gagner en efficacité. A ce point de vue, Nehalem apporte deux améliorations. La première concerne le buffer de ré-ordonnancement (ROB) qui passe de 96 entrées sur Core 2 à 128 sur Nehalem, ce qui permettra au moteur OOO de travailler sur 33% de données supplémentaires et donc, d’avoir des occasions supplémentaires de trouver de meilleurs optimisations dans les µops. La seconde, de loin la plus importante, est le retour du SMT (Simultaneous Multithreading), technologie introduite avec les Pentium 4 et connue sous le nom commercial d’Hyperthreading (HT). Le but est toujours de pouvoir gérer simultanément deux threads (tâches) au sein du cœur pour « boucher les trous » du pipeline et optimiser, ici encore, les performances des unités d’exécutions. Voyons cela :
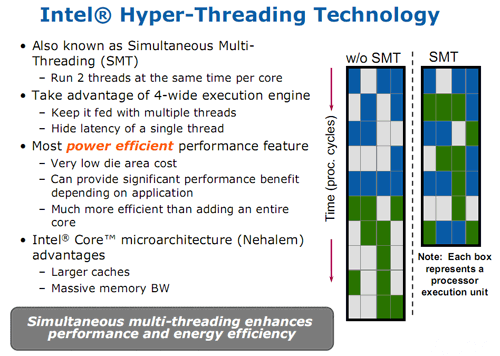
En théorie, l’apport de l’Hyperthreading sur une architecture dotée d’un pipeline court (donc moins sujet aux chutes d’efficacité qu’un pipeline long comme le Pentium 4) est assez réduite. Toutefois, Intel a probablement choisi de rajouter le SMT sur Nehalem à cause des multiples optimisations effectuées sur le front end et sur les caches. Nous verrons un peu plus loin ce qu’il en est des gains obtenus avec l’Hyperthreading.
Reste maintenant à parler des unités d’exécutions en elles-mêmes. Voyons leur schéma :
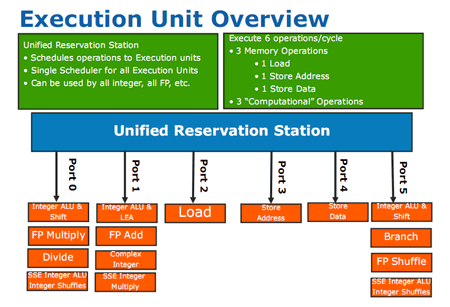
Sans surprise, les execs de Nehalem sont strictement identiques à celles des derniers Core 2. On retrouve ainsi les 3 unités chargés des accès mémoires et les 3 unités de calculs responsables des mêmes opérations. La seule différence provient de la « Unified Reservation Station », chargée de dispatcher les µops sur les différentes unités, dont la capacité augmente légèrement suite à la croissance du moteur OOO. Bien sûr, on trouve aussi dans ces unités le support du SSE 4.2, qui vient compléter le SSE 4.1 des Penryn et apporte 7 nouvelles instructions. Intéressons nous-y un instant :
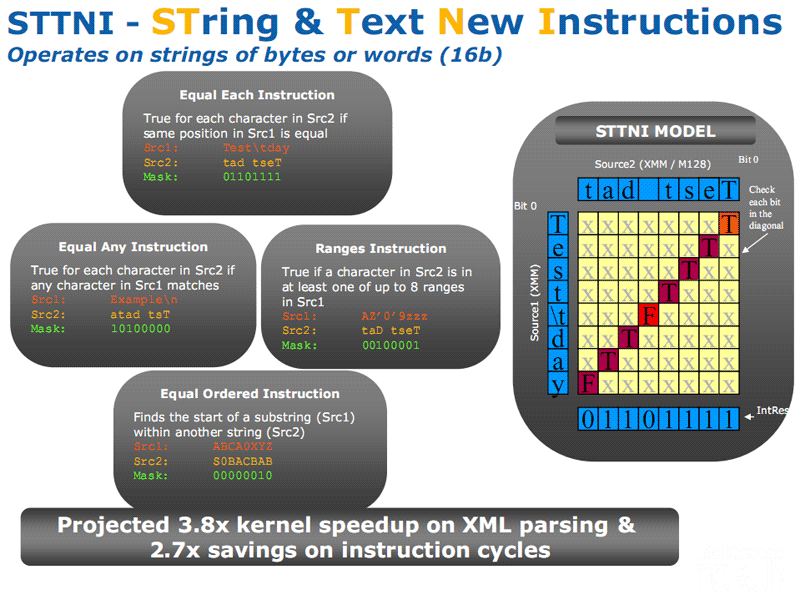 |
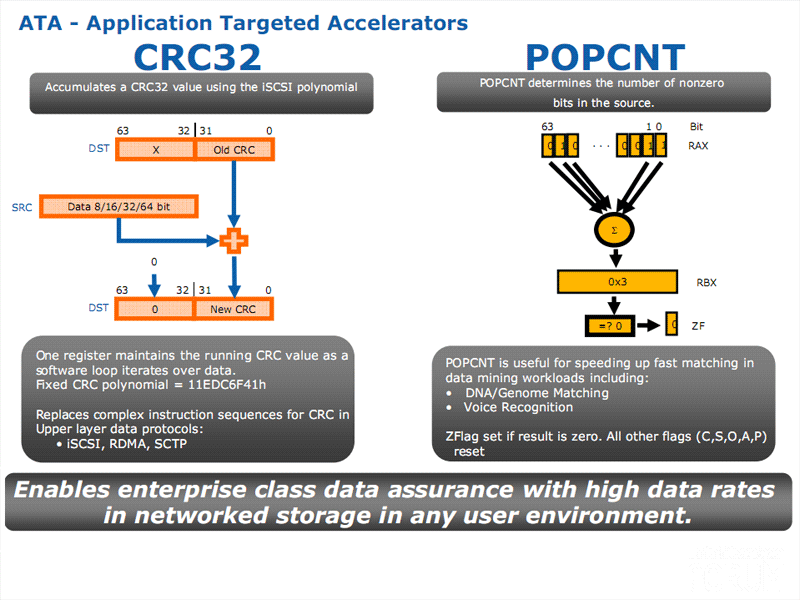 |
Les cinq premières instructions sont regroupées sous le nom STTNI pour « String & Text New Instructions ». Il s’agit des instructions PCMPESTRI (Packed Compare Explicit Length Strings, Return Index), PCMPESTRM (Packed Compare Explicit Length Strings, Return Mask), PCMPISTRI (Packed Compare Implicit Length Strings, Return Index), PCMPISTRM (Packed Compare Implicit Length String, Return Mask) et PCMPGTQ (Compare Packed Data For Greater Than). Celle-ci sont dédiés à traiter des chaine de textes et donc à accélérer le traitement de flux de données composés de chaines de caractères comme le XML. On trouve ensuite l’instruction CRC32, exclusivement destinée à calculer de manière hardware les checksums des protocoles iSCSI et InfiniBand, utilisés dans les serveurs et l’instruction POPCNT qui compte le nombre de bit à « 1 » dans un registre. POPCNT sera utilisée principalement dans la recherche scientifique, voir dans la reconnaissance vocale. A noter que bien qu’étant présentée par Intel comme faisant partie de SSE 4.2, l’instruction POPCNT est déjà présente dans les Core 2 basé sur le cœur « Penryn ».
- Tests pratiques
Voilà donc pour la théorie. Pour en savoir plus sur les modifications apportées par Nehalem sur les cœurs, nous nous sommes livrés à deux tests pratiques afin de savoir si la latence et le débit des instructions ont été modifiés depuis Penryn, et aussi pour mesurer les gains de performances apportés par le retour de l’Hyperthreading. Commençons donc par comparer la façon dont sont traitées les instructions x86 sur ces deux générations :
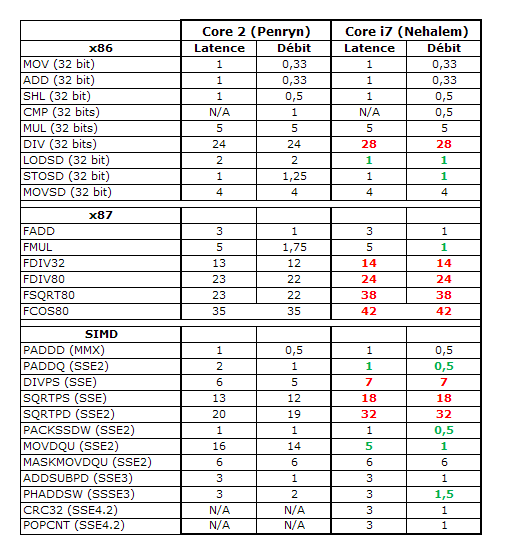
Et le résultat est très instructif. Comme on le constate au premier coup d’œil, Intel a du faire des choix pour Nehalem et visiblement, le beau diviseur ultra-performant qui équipait Penryn s’est retrouvé sérieusement limité. Tout ce qui ressemble de prés ou de loin à une division ou qui utilise le diviseur (racine carrée, fonctions trigonométriques, …etc.) est systématiquement plus lent sur Nehalem que sur Penryn. Toutefois, les résultats obtenus sont tout de même nettement meilleurs que sur Conroe. Ceci peut s’expliquer de cette façon : le développement de Nehalem, nouvelle architecture, a débuté bien avant celui de Penryn, simple die-shrink. Il est donc probable que lorsque le diviseur de Penryn a été finalisé, celui de Nehalem était déjà terminé. Ce qui expliquerait que Nehalem se retrouve avec un diviseur à mi-chemin entre Conroe et Penryn.
 |
Pour le reste, Intel a mis le paquet. Car si les divisions sont loin d’être les instructions les plus utilisées, il n’en est pas de même des LOAD, STORE et autres ADD. Et sur ces instructions, Nehalem fait souvent mieux que Penryn, en latence comme en débit, tout particulièrement en SIMD. Le gain le plus important reste sur les accès non alignés (MOVDQU) ou Nehalem traite l’instruction en un seul cycle là ou il en fallait 14 au Penryn ! Cette nouvelle fonctionnalité est d’ailleurs présentée par Intel comme capable d’offrir des gains de performances très importants. |
Globalement, Intel semble donc avoir optimisé les instructions les plus utilisées, principalement liées aux accès cache et mémoire. Parlons maintenant de l’Hyperthreading. Nous avons effectués quelques benchmarks avec et sans l’HT actif pour comparer le gain apporté par cette technologie sur Nehalem :
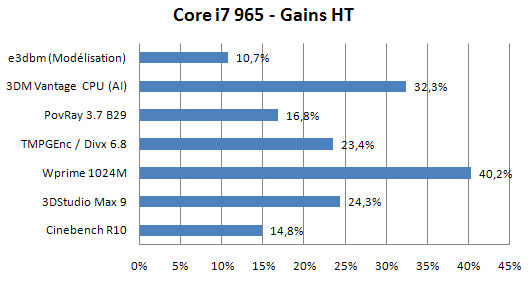
Les résultats sont impressionnants ! Certes, nous n’avons utilisé ici que des applications massivement multi-threadées afin de bien mettre en évidence l’apport du SMT sur l’architecture Nehalem, mais même ainsi, les résultats montrent un gain très important, compris entre 10% et 40% selon l’application, avec l’utilisation de 8 threads. Ce surcroit de performances, ramené à un seul cœur, est comparable à celui obtenu avec les premiers Pentium 4 HT. Intel a donc fait un excellent travail d’optimisation sur le moteur OOO et la gestion des contextes inhérente à l’utilisation du SMT. Bien sûr, inutile d’attendre ce genre de gain dans les applications qui tirent encore peu parti des processeurs multi-cœur comme les jeux, mais l’Hyperthreading représente, dans le cas de Nehalem, une technologie mature dont les gains escomptés sont remarquables.