
| Sommaire: |
![]()
nForce 2 : Les technologies nVidia
- Le successeur du nForce
Le nForce2 reprend les caractéristiques du nForce, en y apportant quelques optimisations ainsi que le support de normes plus récentes. Le tableau ci-dessous résume les différences entre ces deux chipsets.
| nForce | nForce2 | |
| Interface CPU | DASP | DASP |
| Interface Mémoire | TwinBank (DDR266) |
DualDDR (DDR266, 333, 400) |
| AGP | 4X (AGP 2.0) | 4X/8X (AGP 3.0) |
| Controleur sonore | APU, SoundStorm | APU, SoundStorm |
| Réseau | StreamThru, HomePNA 2.0 | StreamThru, HomePNA 2.0, DualNet, contrôleur 3Com intégré |
| Connectique | USB 1.1 | USB 1.1, USB 2.0, Firewire, contrôleur Ultra ATA133 |
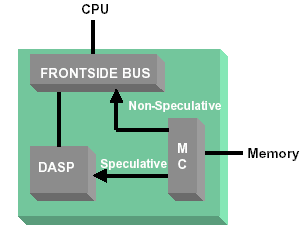
- Le DASP
La technologie DASP (Dynamic Adaptive Speculative Pre-processor), développée exclusivement par nVidia, est un mécanisme de préchargement des données (prefetch), et ce dans le but de diminuer les latences d'accčs ŕ la mémoire centrale.
Comme toutes les techniques de prefetch, le DASP scrute les requętes processeur en vue d'y trouver des modčles récurrents (access patterns). Lorsqu'un modčle d'accčs est reconnu, le DASP utilise une partie de la bande passante mémoire pour charger des données dans son cache interne. Si la requęte du processeur concerne des données préchargées dans le DASP, l'accčs ŕ la mémoire centrale est évité.
Le DASP
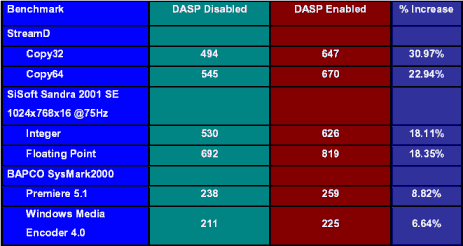
Le gain en cas de succčs est de l'ordre de 40 ŕ 60% par rapport ŕ un accčs mémoire. En utilisation pratique, le taux de succčs du DASP est tel que le gains sont compris entre 6 et 30%, comme le montre le tableau ci-dessous.
- L'architecture mémoire DualDDR
| nVidia a développé pour son chipset nForce une architecture
mémoire originale, dont la particularité est de gérer la DDR sur deux
canaux indépendants. Appelée TwinBank, cette technologie permet
en théorie de doubler la bande passante mémoire. Le nForce2 reprend cette technologie sous le nom DualDDR, et étend le fonctionnement ŕ 333MHz sur 2 fois 64 bits en mode synchrone (débit maximal de 333x8x2 = 5,2Go/s) et ŕ 400MHz en mode asynchrone (soit 6,25Go/s). |
|
Comparons les débits fournis respectivement par le bus EV6, les chipsets SDRAM, DDR et le nForce2, et ce en mode synchrone (FSB et fréquence mémoire identiques). Les valeurs sont exprimées en Mo/s.
| Bus EV6 | Chipset SDRAM | Chipset DDR | Chipset DualDDR | |
| FSB 100MHz | 1600 | 800 | 1600 | 3200 |
| FSB 133MHz | 2133 | 1066 | 2133 | 4266 |
| FSB 166MHz | 2667 | 1333 | 2667 | 5334 |
Comme le montrent ces résultats, les chipsets DDR sont déjŕ en mesure
de fournir la bande passante nécessaire au bus EV6, et on peut alors se
demander quel est l'intéręt de doubler encore la bande passante disponible
sur le bus mémoire, ce surplus n'étant pas exploitable pas le bus processeur.
En réalité, le tableau ci-dessus ne montre que les débits maximums théoriques
fournis par les différentes architecture mémoire. En pratique, les débits
délivrés par la mémoire sont bien inférieurs ŕ ces valeurs, car d'autres
facteurs interviennent, tels que la latence. En effet, la mémoire ne répond
pas instantanément aux requętes du chipset, et il lui faut un certain
nombre de cycles afin de commencer ŕ transmettre les données sur le bus.
Si la latence est maximale lors du premier accčs, les accčs suivants sont
pour leur part plus rapides, bien que non instantanés. Considérant les
vitesses de fonctionnement des mémoires actuelles, l'influence de la latence
sur les performances de la mémoire est de plus en plus importante. Le
réglage des timings mémoire influe de façon directe sur la latence, ŕ
tel point que changer l'un des paramčtres de timing peut avoir des conséquences
importantes sur la mesure de débit.
La technologie DualDDR permet, par rapport ŕ un chipset DDR classique,
de diminuer la latence de la mémoire vue depuis le chipset. Le nForce2
comprend en effet deux contrôleurs mémoire indépendants, c'est-ŕ-dire
capable de répondre indépendamment l'un de l'autre aux requętes du processeur.
Regardons ce qui se passe lors d'une requęte de lecture en mémoire dans
le cas d'un chipset DDR sur simple canal. Le processeur envoie un signal
au contrôleur mémoire, qui transmet la requęte ŕ la mémoire. Du fait de
sa latence, celle-ci ne répondra pas instantanément, bloquant ainsi toute
requęte supplémentaire et mettant le contrôleur mémoire en état d'attente.
Toute requęte supplémentaire sera ainsi bloquée (ou du moins mise en cache),
et ce jusqu'ŕ ce que le bus mémoire soit ŕ nouveau disponible.
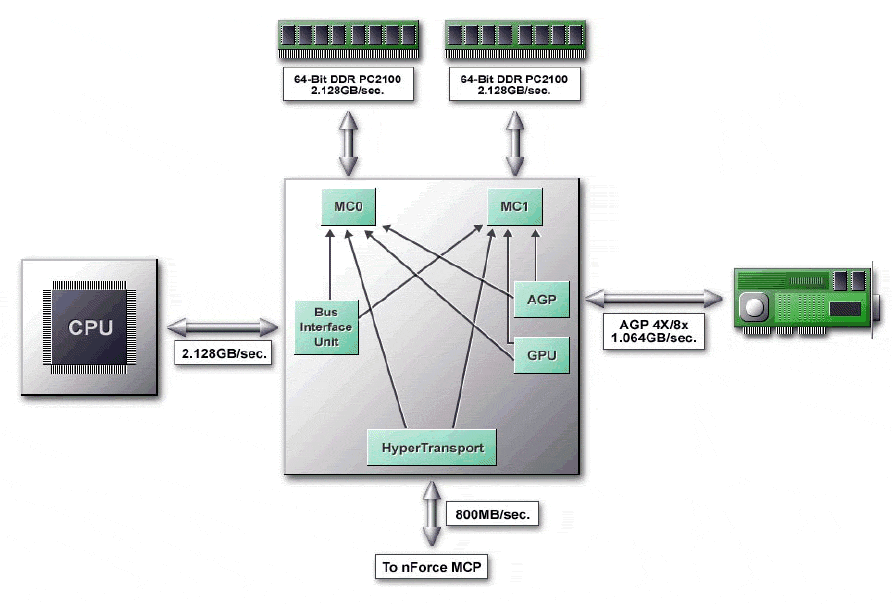
Dans le cas de deux contrôleurs mémoire, la seconde requęte pourra ętre
prise en charge par le second contrôleur. Alors que le premier contrôleur
addressant la premičre barrette mémoire est occupé, le second contrôleur
rattaché ŕ la seconde barrette est disponible et en mesure de prendre
en charge la requęte du processeur. La latence de la premičre requęte
est donc masquée, et vue depuis le processeur, la latence globale est
divisée par deux.
L'architecture TwinBak du nForce1
Ceci semble merveilleux en théorie, mais en pratique le bon fonctionnement conjoint des deux contrôleurs nécessite certaines conditions, et notamment que les données lues lors des deux requętes ne concernent pas la męme barrette. De plus, il faut assurer la cohérence entre les données lues et écrites par ces deux contrôleurs, ce qui représente une étape de vérification supplémentaire dans le traitement.
Quoiqu'il en soit, la technique semble effciace, et le chipset nForce
est réputé pour les bonnes performances mémoires que ce mécanisme permet,
et nVidia annonce une amélioration du systčme avec le nForce2, par l'utilisation
d'algorithmes plus aggressifs.
Un point trčs important est ŕ noter ŕ ce sujet
: les algorithmes d'optimisation utilisés par le nForce2 ne fonctionnent
qu'en mode synchrone, c'est-ŕ-dire lorsque le FSB et le bus mémoire
tournent ŕ la męme fréquence. On
peut facilement comprendre le phénomčne lorsque le bus mémoire tourne
ŕ une vitesse inférieure au FSB (FSB de 166 et bus mémoire ŕ 133 par exemple),
mais c'est également le cas lorsque le bus mémoire tourne plus vite que
le FSB. Ce dernier cas de figure est couramment utilisés par les chipsets,
afin d'augmenter le débit mémoire tout en gardant un FSB dans les limites
des spécifications du chipset ; ce n'est pas le cas du nForce2.
nVidia justifie cela par le fait que la désynchronisation engendre des
cycles de pénalités, nécessaires ŕ la re-synchronisation, et ne permet
ainsi pas un fonctionnement optimal des échanges entre le processeur,
les deux contrôleurs et le bus mémoire. Nous vérifierons bien entendu
cela lors de nos tests.
Comme on le voit sur le shéma sur nForce1 ci-dessus, les deux contrôleurs mémoires sont exploitables par le bus processeur mais également par le bus AGP, et tout particuličrement par le GPU intégré de la version IGP des chipsets nVidia. Si le bus processeur n'est pas capable d'exploiter pleinement la bande passante offerte par les deux contrôleurs, le GPU en revanche tire le plus grand bénéfice de l'interface 128 bits. Ce n'est bien sűr pas le cas sur l'A7N8X qui n'intčgre pas de processeur graphique (version SPP du nForce2), mais les deux contrôleurs mémoire restent exploitables par le bus AGP et l'interface "Hyper-Transport" entre le nForce2 et le MCP-T.