
| Sommaire: |

Etude du Noyau K8
Un petit coup d'oeil à ce magnifique schéma ...
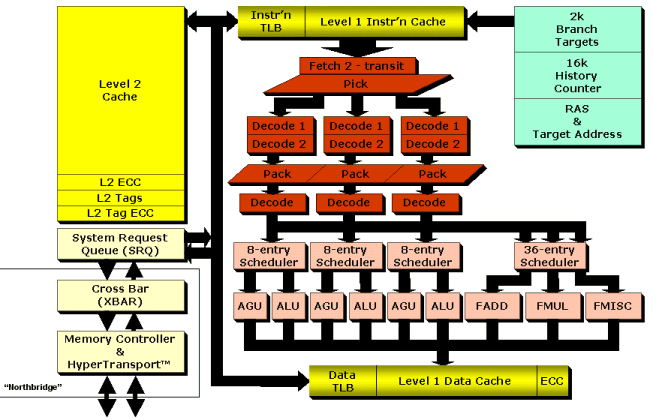
... nous conforte dans l'idée que le noyau du K8 ressemble fortement à celui du K7. On y retrouve 3 unités de décodage des instructions, 3 unités entières et 3 unités flottantes.
Un différence concerne cependant le découpage du pipeline.
Le K7 possède une particularité assez intéressante
: le pipeline de traitement des instructions se scinde en deux pipelines,
l'un destiné aux instructions entières, l'autre aux instructions
flottantes.
Les 6 premiers niveaux du pipeline, qui forment l'étage "Fetch/Decode",
sont communs aux deux type d'instructions. Le second étage du pipeline
("Exec") concerne le traitement par les unités de calcul
; il comporte 4 étapes pour les instructions entières (ce
qui donne une profondeur totale de 10 étapes) et 9 étapes
pour les instructions flottantes (soit une profondeur totale de 15 étapes).
Ce faisant, les calculs entiers ne souffrent pas d'un pipeline trop profond,
et les calculs flottants ne limitent pas la montée en fréquence
du processeur.
Le K8 reprend le même schéma du double pipeline, mais y ajoute deux niveaux, ce qui porte à 12 niveaux pour les calculs entiers et 17 niveaux pour les calculs flottants.
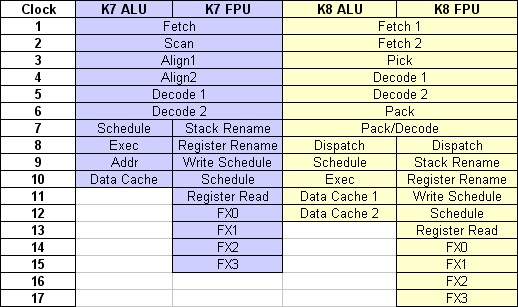
Les pipelines du K7 et du K8
L'étage commun "Fetch/Decode" du K8 a ainsi subi un redécoupage, et est passé de 6 à 7 niveaux. Il comprend désormais une phase supplémentaire de regroupement des instructions ("pack") avant de les envoyer à l'étage suivant, et ce afin d'optimiser la répartition sur les différentes unités de calcul.
Voyons en détail le cheminement des instructions dans le pipeline du K8 :
- L'extraction des instructions (fetch)
s'effectue en étroite collaboration avec le cache code L1 et
le mécanisme de prédiction de branchement. L'étage
de fetch est capable de fournir 16 octets d'instructions aux trois décodeurs.
- Les décodeurs convertissent
les instructions x86 en micro-opérations (µOPs) de longueur
fixe. L'étage de décodage est ainsi capable de fournir
3 µOPs par cycle.
On distingue à ce stade les instructions "simples" qui se décodent en au plus deux µOPs. Le décodage de ces instructions est effectué en hardware, les µOPs issues du décodage sont packées, et les packs ainsi formés sont distribués sur les unités de calcul (dispatch). On appelle ce chemin le FastPath.
Les instructions qui se décodent en plus de deux µOPs, dites complexes, sont décodées par la ROM interne, ce qui nécessite davantage de temps. On dit alors que ces instructions sont microcodées.En comparaison au K7, le K8 traite plus d'instructions par le FastPath, et notamment des instructions SSE. AMD annonce une baisse des instructions microcodées de 8% pour les instructions entières et de 28% pour les instructions flottantes.
- Les µOPs sont ainsi réparties sur les unités
de calcul. Le K8 comporte ainsi :
- Trois unités de calcul d'adresses mémoire (AGU)
- Trois unités de calcul entier (ALU). Ces unités sont capables d'effectuer la plupart des opérations simples en un cycle d'horloge, et ce en 32 et en 64 bits : addition, rotation, décalage, opérations logiques (et, ou). La multiplication entière nécessite quant à elle 3 cycles de latence en 32 bits et 5 cycles en 64 bits.
- Trois unités de calcul flottant (FPU),
qui traitent les µOPs x87, MMX, 3DNow!, SSE et SSE2.
- La dernière phase du traitement consiste en la récupération des données depuis le cache de données L1 et/ou l'écriture du résultat. Le cache L1 est de type dual-ported, ce qui signifie qu'il supporte deux lectures/écritures 64 bits) chaque cycle. Nous verrons cette caractéristique de façon concrète dans les tests de débit des caches.
Ces améliorations apportées au noyau du K8 permettent de
combler quelques lacunes du noyau K7, notamment en ce qui concerne les
performances en SSE. Mais les innovations les plus importantes du K8 et
qui le distinguent le plus de son prédécesseur sont en fait
extérieures au noyau, comme nous l'avons vu.