
| Sommaire: |

Etude des caches :
Fonctionnement
1) Le cache L1
| CPU | K8 | Athlon XP | Pentium 4 NWD | Pentium 4 PSC |
| Taille | code : 64Ko données : 64Ko |
code : 64Ko données : 64Ko |
TC : 12Kµops données : 8Ko |
TC : 12Kµops données : 16Ko |
| Associativité | code : 2 voies données : 2 voies |
code : 2 voies données : 2 voies |
TC : 8 voies données : 4 voies |
TC : 8 voies données : 8 voies |
| Taille d'une ligne | code : 64 octets données : 64 octets |
code : 64 octets données : 64 octets |
TC : n.a données : 64 octets |
TC : n.a données : 64 octets |
| Mode d'écriture | Write Back | Write Back | Write Through | Write Through |
| Latence (données constructeur) |
3 cycles | 3 cycles | 2 cycles | 4 cycles |
Les caches de premier niveau du K8 (L1 données et L1 code) sont
en tout point semblables à ceux du K7. Cela semble finalement assez
logique dans la mesure où les noyaux sont également très
semblables. Ce cache L1 commun aux deux processeurs est très efficace,
essentiellement grâce à sa taille élevée. Il
est de type associatif à 2 voies, ce qui en résulte une
organisation en deux blocs de 32Ko. Une telle taille permet de contenir
une grande quantité de données ou de code contigus, mais
la faible associativité tend à augmenter les conflits de
cache.
2) Le cache L2
| CPU | K8 | Athlon XP | Pentium 4 NWD | Pentium 4 PSC |
| Taille | 512Ko (NewCastle) 1024Ko (Hammer) |
256 ŕ 512Ko | 512Ko | 1024Ko |
| Associativité | 16 voies | 16 voies | 8 voies | 8 voies |
| Taille d'une ligne | 64 octets | 64 octets | 64 octets | 64 octets |
| Latence (données constructeur) |
? | 8 cycles | 7 cycles | 11 cycles |
| Largeur du bus | 128 bits | 64 bits | 256 bits | 256 bits |
| Relation avec le L1 | exclusive | exclusive | inclusive | inclusive |
Les caches L2 des K7 et K8 partagent de nombreuses caractéristiques, notamment une associativité à 16 voies qui permet de compenser en partie l'associativité deux voies du cache L1.
Le bus d'échange entre le noyau et le cache L2 passe de 64 bits
sur K7 à 128 bits sur le K8, ce qui devrait permettre une augmentation
du débit du cache L2. Sur le K7, ce bus a été dimensionné
en tenant compte des spécificités des caches L2 des premiers
Athlon à cache externe, et commence a montrer ses limites sur les
modèles à cache intégré. L'augmentation de
la largeur du bus devrait avoir un impact direct sur le débit du
cache L2, ce que nous ne manquerons pas de vérifier.
Le K8 comporte également un mécanisme de prefetch hardware,
qui met à profit les moments d'inactivité du bus mémoire
pour en remonter des données dans le cache L2.
Une des caractéristiques les plus marquantes du cache L2 des K7 et K8 est sa relation exclusive avec le cache L1, ce qui les distingue des processeurs Intel qui adoptent une relation de type inclusive. L'occasion se présente donc d'expliquer en quoi ces deux modes de fonctionnement se distinguent dans la pratique, ainsi que de connaître les points forts et les points faibles de chaque système.
3) Caches inclusifs et exclusifs
Afin de bien comprendre le fonctionnement d'un cache, considérons le cas hypothétique d'un processeur possédant un seul niveau de cache. Lorsqu'arrive une requête en lecture, le processeur va interroger son cache. Si la donnée ne s'y trouve pas, il va alors la chercher en mémoire, et en même temps qu'elle y est récupérée elle est copiée dans le cache. Pourquoi cela ? car le processeur suppose que s'il a eu besoin de cette donnée, il en aura encore besoin sous peu. Un processeur x86 possède peu de registres, et la valeur récupérée qui se trouve alors dans un registre n'y restera pas plus de quelques cycles ; la stocker dans le cache permettra ainsi au besoin de la récupérer rapidement.
Avec un niveau de cache, une requête en lecture du processeur se traduit par deux états possibles :
- Lorsque la donnée requise est dans le cache, il y a succès
du cache. C'est bien sûr le cas le plus favorable.
- Si la donnée requise n'est pas dans le cache, il y a alors échec du cache. La phase qui suit consiste à récupérer la donnée depuis la mémoire, et au passage elle est copiée dans le cache. C'est la phase de mise en cache, ou remplissage du cache. Deux cas se présentent alors, selon que le cache soit plein ou non. S'il ne l'est pas, une ligne supplémentaire est remplie :
Figure 1 : mise en cache
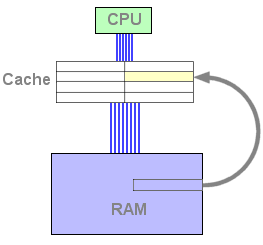
La chose se complique lorsque le cache est plein, car alors la mise en cache nécessite de remplacer une ligne déjà occupée. Afin de choisir quelle ligne va être évincée, le processeur se base sur un algorithme de remplacement, le choix le plus courant consistant à remplacer la ligne la moins récemment utilisée ; c'est l'algorithme LRU, pour Least Recently Used.
Figure 2 : Eviction d'une ligne de cache
Cliquez sur Actualiser ou F5 pour lancer l'animation.
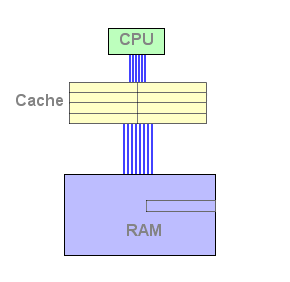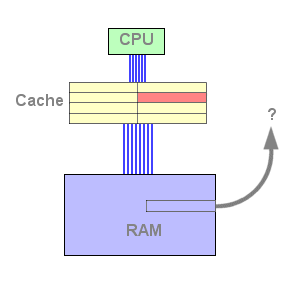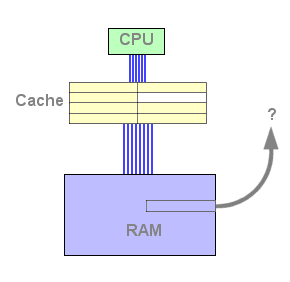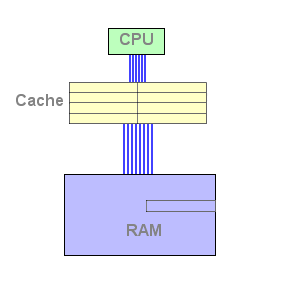
Comme on le constate sur le schéma, la ligne évincée
du cache L1 est alors perdue. Le rôle premier d'un cache de second
niveau est de récupérer cette ligne évincée,
afin de permettre sa récupération rapide au besoin. Un rôle
de poubelle en quelquesorte.
L'ajout d'un second niveau de cache se traduit par des états supplémentaires lors d'une requête en lecture :
- la donnée est dans le L1 : succès du L1
- la donnée n'est pas dans le L1 mais est trouvée dans le L2 : échec du L1, succès du L2
- la donnée n'est ni dans le L1 ni dans le L2 : échec des L1 et L2
Lorsque le cache L1 n'est pas plein, la phase de mise en cache est similaire à la configuration à un seul niveau :
Figure 3 : mise en cache
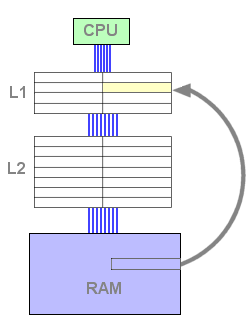
Ce n'est que lorsque le L1 est plein que le cache L2 a un rôle actif : lorsqu'une ligne est évincée du L1, celle-ci est stockée dans le L2, et une nouvelle ligne issue de la mémoire occupe la place ainsi libérée dans le L1 :
Figure 4 : Remplissage du L2
(Cliquez sur Actualiser ou F5 pour lancer l'animation)
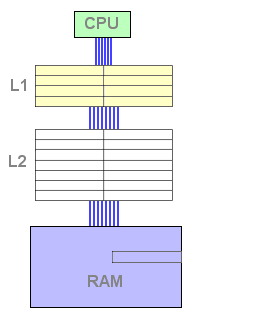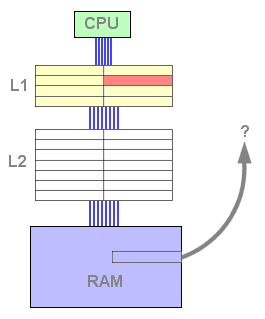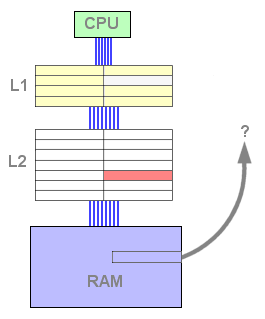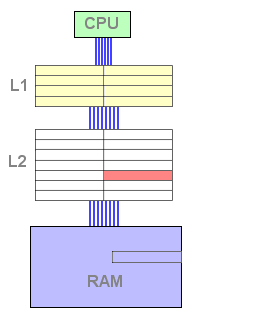
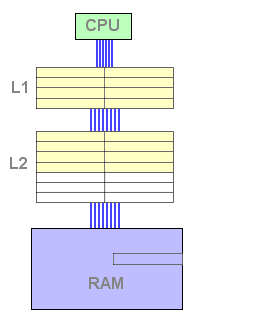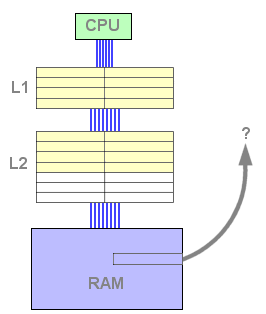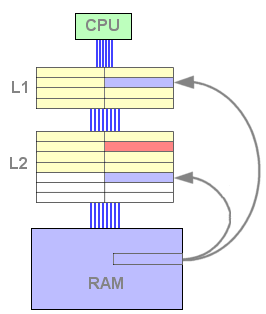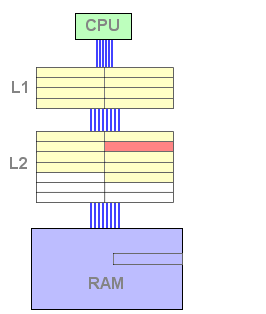
Dès ce moment, le cache L2 contient des données et est susceptible de répondre positivement à une requête de lecture. Dès lors, si la donnée recherchée n'est pas trouvée dans le L1 mais l'est dans le L2, une ligne doit être libérée dans le L1 afin d'accueillir la ligne issue du L2. La ligne évincée est copiée dans un emplacement libre du L2, puis la ligne concernée du L2 est remontée dans le L1 et invalidée dans le L2 afin de libérer de la place :
Figure 5 : Echec du L1, succès du L2
Cliquez sur Actualiser ou F5 pour lancer l'animation.
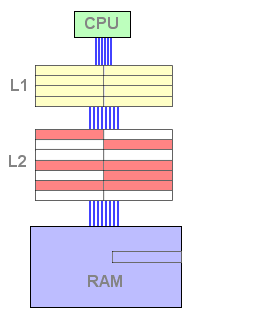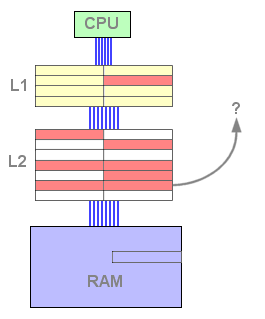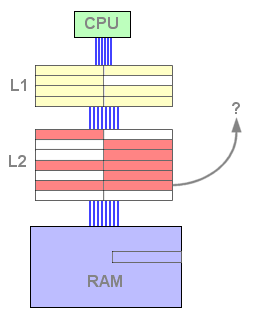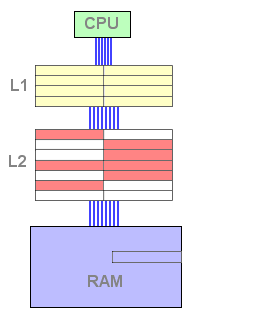
Dans ce mode de fonctionnement, on remarque qu'une ligne de cache n'existe jamais conjointement dans les deux niveaux mais qu'elle passe de l'un à l'autre, plusieurs fois si nécessaire. Les caches n'interfèrent pas, et une donnée se trouve exclusivement dans l'un des deux niveaux : c'est un cache exclusif. La taille totale du cache efficace est donc égale à la somme des tailles des deux niveaux. De plus, aucune contrainte de taille n'existe entre les deux niveaux de cache, le système fonctionne même si le cache de second niveau est d'une taille inférieure au premier niveau.
La relation exclusive permet ainsi une grande souplesse, mais elle présente
un inconvénient en terme de performances : en effet, en cas de
succès en lecture dans le cache L2, une ligne du L1 doit y être
écrite avant de récupérer la donnée depuis
le L2. Cette écriture est assez pénalisante en terme de
cycles et ralentit le temps total de récupération depuis
le L2.
Afin de pallier à ce problème, les caches exclusifs sont
très souvent accompagnés d'un victim buffer
(VB), qui est une mémoire de très petite taille
insérée entre le L1 et le L2. Les lignes évincées
du L1 sont ainsi envoyées vers le VB plutôt que vers le L2.
Le VB étant d'accès très rapide, la récupération
d'une donnée s'y trouvant est à peine plus lente que depuis
le L1. Ainsi, en cas de récupération d'une donnée
depuis le L2, la ligne évincée du L1 est copiée dans
le VB et non dans le L2, ce qui accélère les performances.
Le VB présente une bonne amélioration du mode exclusif, mais son intérêt est limité par sa taille bien souvent assez réduite (d'une dizaine d'entrées en général). Qui plus est, lorsque le VB est plein, les lignes qu'il contient sont mises à jour dans le cache L2, ce qui représente une phase supplémentaire dans le traitement. Pour terminer, la présence du VB accélère la phase d'écriture, mais ne la supprime pas pour autant.
Réfléchissons quelques instants : pour éviter cette phase d'écriture dans le L2 en cas d'éviction, il faudrait que la donnée à évincer soit déjà dans le cache L2. Comment cela est-il possible ? Il suffit en fait de copier la donnée dans le L2 lors de la phase de mise en cache. Voyons cela :
Dans cette configuration, lorsqu'une donnée est remontée depuis la mémoire centrale elle est copiée dans le L1 et dans le L2. En ce sens, la mise en cache nécessite une copie supplémentaire par rapport au mode exclusif.
Figure 6 : Mise en cache
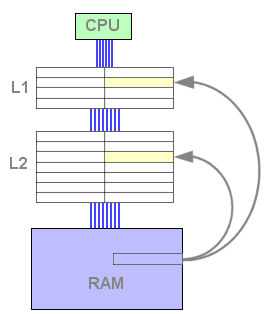
Lorsque le L1 est plein et que la donnée demandée ne se
trouve ni dans le L1 ni dans le L2 (échec L1, échec L2),
une nouvelle ligne est copiée depuis la mémoire dans les
deux niveaux. La ligne remplacée dans le L1 n'est pas sauvée
dans le L2 car elle s'y trouve déjà. On a donc le même
nombre de copies par rapport à la même opération dans
le mode exclusif.
A partir de là, le cache L2 contient des informations qui ne sont
pas présentes dans le L1.
Figure 7 : Echec L1 et L2
Cliquez sur Actualiser ou F5 pour lancer l'animation.
Lorsque la donnée n'est pas trouvée dans le L1 mais l'est dans le L2 (échec L1, succès L2), la seule opération consiste à remplacer une ligne de cache du L1 par une ligne du L2. On économise ainsi l'écriture de la ligne évincée dans le L2.
Figure 8 : Echec L1 et succès L2
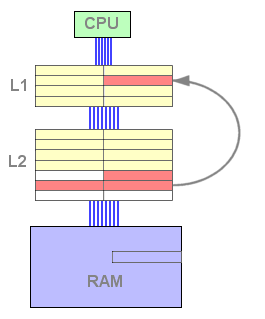
Dans ce mode de fonctionnement, toutes les lignes présentes à
chaque instant dans le L1 sont également dans le L2, ce qui revient
à dire que le L2 inclut une image du L1. C'est le mode inclusif.
Un cache L2 inclusif présente l'avantage d'éviter la phase
d'écriture en cas de succès en lecture, ce qui le rend significativement
plus performant qu'un cache exclusif dans cette phase. Le revers de la
médaille est la redondance des lignes de cache : le contenu du
L1 se trouve dupliqué dans le L2, ce qui réduit d'autant
la capacité "utile" du L2 (c'est-à-dire capable
de fournir une donnée qui n'est pas dans le L1). On en déduit
tout naturellement que le cache L2 doit avoir une capacité supérieure
à celle du L1, et son efficacité dépend directement
de cette différence de taille.
3) Avantages et inconvénients de chaque méthode
Résumons les points forts et les points faibles d'un cache exclusif :
+ |
- |
|
|
Considérant cela, on peut établir ce à quoi il doit ressembler pour fournir les performances maximales :
- Un cache L1 de grande taille. Cela est rendu possible par l'absence
de contrainte sur les tailles des différents niveaux. De plus,
un L1 de grande capacité permet de limiter l'accès au
cache L2.
- Un victim buffer afin de différer la mise à jour dans le L2.
AMD utilise un cache L2 exclusif sur la gamme K7 depuis le Thunderbird.
L'architecture du processeur est conforme à un tel choix avec un
cache L1 de grande taille (deux fois 64 Ko). AMD a également recours
à un victim buffer à 8 entrées.
Ce choix lui a permis à de produire des processeurs embarquant
de 64 à 512 Ko de cache L2, et ce avec le même noyau K7,
tout en gardant de bonnes performances. Ce choix a été bénéfique,
mais commence à présenter quelques lacunes. En effet, le
mode exclusif n'exploitant pas de façon optimale le cache L2, l'inflation
de celui-ci ne s'accompagne pas d'un gain de performances spectaculaire.
Preuve en est le Barton, dont les 512 Ko de cache L2 ne procurent pas
un gain remarquable par rapport à la version 256 Ko. Compte tenu
de l'investissement en transistors que cela représente, c'est fort
regrettable !
En comparaison, le cache inclusif présente les avantages et inconvénients suivants :
+ |
- |
|
|
L'avantage du mode inclusif réside avant tout dans les performances
qu'il procure, à condition bien sûr que les contraintes que
nous avons évoquées soient respectées.
La contrainte du rapport de taille entre le L1 et le L2 nécessite
tout d'abord que le L1 soit de taille réduite, ce qui a une influence
directe sur son taux de succès, donc sur ses performances. C'est
là qu'est le dilemme du mode inclusif : plus le cache L1 est de
grande taille plus il est efficace, mais plus le L2 doit être de
grande taille également pour garder son efficacité.
Ensuite, les performances du mode inclusif dépendent fortement
de celles du cache L2 : le gain de performances d'un cache inclusif résidant
dans la lecture dans le L2, il est d'autant plus important que le cache
L2 est efficace, c'est-à-dire de grande taille et bien géré.
A l'inverse, un cache L2 de petite taille et/ou mal géré
peut littéralement nuire aux performances d'un cache inclusif !
Intel a pris le pari du mode inclusif depuis le Pentium Pro. En conséquence,
aucun processeur de cette gamme (et des suivantes) n'a eu un cache L1
de grande taille, et pour cause. La plus grande taille de L1 est atteinte
avec le Pentium M (2 fois 32Ko), mais celui-ci est secondé par
un cache L2 de 1Mo ! Avec l'avénement du Pentium 4, Intel a même
diminué la taille du L1, avec seulement 8 Ko pour le cache de données.
Choix risqué, mais finalement logique : quitte à avoir un
cache de petite taille, autant le faire tout petit, mais très rapide.
Le L1 du Pentium 4 est en revanche le plus rapide qui soit, avec une latence
d'accès de 2 cycles. Le mode inclusif permet au cache L2 de combler
la faible taille du L1.
Dans les faits, ce choix s'est avéré parfois bénéfique,
parfois catastrophique. Le mode inclusif impose certaines contraintes
sur le cache L2, ce qui d'un point de vue commercial ne permet pas facilement
de décliner une gamme de processeurs autour d'un même noyau.
Intel a quand même sorti le Céléron P4, dont le cache
L2 de 128 Ko géré en 2 voies associatives seulement a littéralement
tiré les performances vers le bas. Le Céléron P4
ne respecte pas les contraintes du mode inclusif, et le résultat
est catastrophique. A l'inverse, le Pentium M avec son Mo de cache L2
s'avère une réussite totale, dévoilant tout le bénéfice
du mode inclusif dans ce cas.
4) Conclusion
Le choix d'un système de cache inclusif ou exclusif représente un choix important dans le design d'un processeur. Il conditionne les performances, mais également l'évolutivité vers les deux extrêmes de gamme. Le mode exclusif est le plus flexible, au détriment de performances optimales que seul le mode inclusif peut atteindre. En revanche, ce mode souffre de nombreuses contraintes, et ne pas les respecter peut avoir l'effet inverse recherché, à savoir une perte de performances.