
| Sommaire: |

Technologie AMD64 en détail
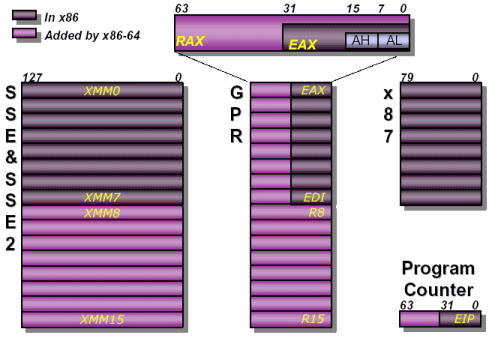
1) Augmentation des GPR (8 -> 16)
L'AMD64 propose un nouveau mode d'exploitation x86, succédant à l'IA32. La démarche entreprise par AMD présente de nombreux points communs avec celle proposée par le 386 lors de l'avènement du 32 bits.
En premier lieu, l'AMD64 propose une extension "horizontale" en augmentant la taille des GPR à 64 bits. Les GPR sont bien entendu utilisables sous leurs formes 8, 16 et 32 bits, ce qui assure au K8 la compatibilité descendante. Lorsque le processeur est basculé dans un mode d'exploitation appelé "long mode", le système a alors accès aux registres sous leur forme 64 bits. C'est cette caractéristique qui vaut l'attribut de 64 bits aux processeurs K8. Cette extension horizontale a les conséquences directes suivantes :
- la gestion des entiers 64 bits de façon native.
- l'augmentation de la capacité de mémoire adressable.
Ces deux caractéristiques sont intéressantes, mais à long terme, car elles ne pallient pas à une faiblesse urgente de l'architecture IA32.
Mais l'AMD64 apporte un plus que n'a pas apporté le 386 en son
temps : une extension verticale, c'est-à-dire que lorsqu'il est
exploité en mode 64 bits, le K8 propose non plus huit mais seize
GPR.
Cette extension du nombre de GPR est certainement une des caractéristiques
les plus importantes de l'AMD64, qui lui donne dans l'immédiat
un intérêt plus grand que la seule augmentation de taille
des GPR à 64 bits. Le surplus de GPR facilite le travail des compilateurs
et évite les nombreuses instructions de sauvegarde des registres.
Au final, le code est plus court, donc plus efficace, donc plus rapide.
Cette extension verticale n'a pas de rapport direct avec le qualificatif
"64 bits" de l'AMD64, et cependant c'est celle qui risque d'avoir
l'impact le plus important à court terme. Cela nous amène
à mettre en garde le lecteur contre les raccourcis que l'on peut
lire ça et là sur l'intérêt actuel de la technologie
64 bits. L'AMD64 c'est bien sûr une extension des GPR à 64
bits, mais ce n'est pas que ça !
En plus des GPR, AMD a également jugé opportun d'augmenter le nombre de registres 128 bits SSE/SSE2, portant leur nombre total à 16 lorsque le processeur est exploité en mode 64 bits. En revanche, le nombre de registres flottants x87 reste inchangé, comme le montre le schéma ci-dessus. Nous étudierons les raisons d'un tel choix dans le paragraphe suivant.
2) La transition du 32 vers le 64 bits
Un des principaux défis du K8 a consisté à en faire un processeur inaugurant une nouvelle architecture 64 bits, et cela tout en fournissant les performances maximales avec les systèmes et applications 32 bits actuels.
Pour ce faire, nous verrons dans ce chapitre que l'architecture AMD64 n'a pas été créée à partir d'une page blanche, mais qu'elle repose en très grande partie sur l'architecture IA32 existante.
Bien entendu cela ne fait pas de l'AMD64 un mode d'exploitation 64 bits comparable à l'IA64, qu'Intel essaie de promouvoir au travers de son Itanium, en ce sens que l'AMD64 présente de nombreuses restrictions liées à son héritage 32 bits. En revanche, cet héritage permet une grande souplesse dans la transition 32 vers 64 bits, souplesse nécessaire à AMD pour imposer son processeur, et par là-même sa nouvelle architecture au sein du grand public.
3) Les différents modes d'exploitation du K8
Le K8 possède fondamentalement deux modes d'exploitation distincts : le "legacy mode" (ou mode "héritage", sous lequel le K8 se comporte comme n'importe quel processeur IA32), et le "long mode", le mode 64 bits. Le tableau ci-dessous résume les différents modes supportés par le K8.
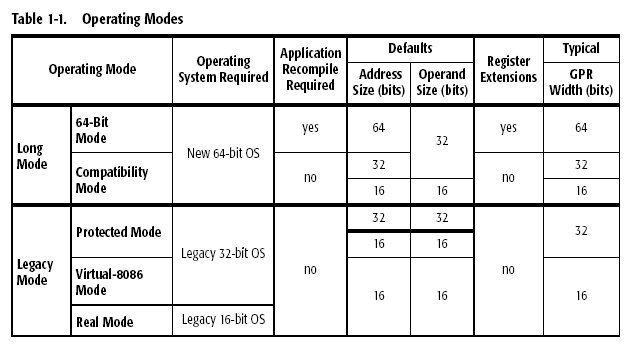
- Le "legacy mode" se passe de toute explication,
il s'agit du mode 32 bits classique, exploité par les OS disponibles
aujourd'hui. Sous cet environnement, le K8 se comporte comme un Athlon
XP gonflé avec les quelques améliorations d'architecture
interne que nous avons abordées lors de l'étude du noyau.
Comme tous les processeurs IA32, le K8 peut alors adresser 4Go de mémoire
physique. Grâce au mécanisme d'extension des adresses physiques
(PAE, pour "Physical Address Extension"), l'espace d'adressage
s'étend à 52 bits, permettant au K8 d'adresser 4096To,
soit 4Po (peta octets) de mémoire virtuelle.
A noter que le K8 fonctionne également en mode réel ; vous pouvez donc faire tourner un K8 sous MS-DOS.
- Le "long mode" est quant à lui le
mode d'exploitation étendu du K8. Pour donner une image, il est
au mode protégé ce que le mode protégé est
au mode réel. Le processeur doit donc être "basculé"
dans ce mode par le système d'exploitation, ce qui implique donc
que ce dernier soit spécifiquement prévu pour gérer
le mode 64 bits ; il existe à l'heure actuelle deux versions
de Windows et une version de Linux destinées à l'exploitation
de l'AMD64.
Le long mode possède un sous-mode, appelé mode de compatibilité (Compatibility Mode), et qui permet au système d'exploitation de faire tourner toutes les applications 32 bits existantes. Bien entendu, ces applications restent soumises aux contraintes liées au mode 32 bits, notamment en ce qui concerne la quantité de mémoire adressable. Ce mode de compatibilité est possible grâce à la surcouche WoW64, qui signifie Windows on Windows 64. L'intérêt majeur de ce mode de compatibilité est qu'il s'opére sans la moindre perte de performances. Pour nous en assurer, nous avons lancé des programmes de benchs en 32 bits sous une version AMD64 de Windows Server 2003, et les scores sont en effet strictement identiques à ceux obtenus sous Windows XP. Cela est évidemment possible parce que l'AMD64 repose sur l'IA32, permettant au code IA32 de tourner sans émulation sous un noyau 64 bits. Wow64 crée une fenêtre de mémoire virtuelle adressable en 32 bits pour ces applications, et celles-ci tournent comme sur un OS 32 bits.
Seule ombre au tableau : Wow64 ne peut évidemment pas encapsuler les applications qui tournent au même niveau de privilège que lui-même, et notamment les drivers système. Cela a pour conséquence que les drivers système doivent être compilés en mode 64 bits, afin de tourner de façon native sur les OS AMD64. La conséquence est fâcheuse : ces systèmes nécessitent des drivers spécifiques. Tout comme cela a été le cas pour Windows XP à son introduction (mais pour d'autres raisons que celles invoquées plus haut), il faudra attendre quelques mois pour voir les drivers 64 bits se généraliser, et nombre de matériels seront inexploitables sous les OS AMD64.
4) De huit à seize GPR
Seize GPR représentent certes une avancée appréciable
par rapport à l'IA32. On peut juste se demander pourquoi AMD n'a
pas été plus loin dans cette démarche en augmentant
le nombre de GPR en mode 64 bits à plus de seize registres.
La raison de ce choix réside dans l'héritage IA32 du K8.
Le défi pour AMD n'a pas consisté à se demander combien
de GPR étaient nécessaires à une utilisation 64 bits,
mais plutôt comment étendre le nombre de GPR de huit à
seize tout en gardant une parfaite compatibilité IA32. Voyons comment
AMD s'y est pris.
L'encodage des instructions IA32 s'effectue par un octet dans lequel sont codés les registres source et destination des intructions ; c'est l'octet ModRM, acronyme de "Mode / Register / Memory". Sur les 8 bits de cet octet, trois bits encodent le registre source et trois bits encodent le registre destination. Et avec trois bits, on peut encoder huit valeurs différentes, qui correspondent aux huit GPR de l'IA32. Pas question bien sûr de modifier cet octet ModRM, sous peine de rendre le processeur incompatible avec les applications 32 bits. Afin d'encoder 16 registres sources et destination, il manque un bit à chaque partie du registre ModRM, et chacun de ces bits se trouve dans un octet de préfixe, appelé REX, et qui est spécifique à l'exploitation en mode 64 bits. Un autre bit est également nécessaire dans le cas d'instructions faisant intervenir une opérande mémoire, et ce sont au final trois bits d'extension qui permettent la gestion 64 bits.
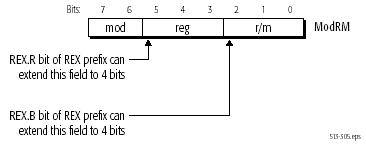
On comprend aisément que la tâche n'était pas simple
pour étendre l'IA32 à la gestion de 16 GPR, voilà
pourquoi il n'y a que huit GPR supplémentaires. Cela étant,
16 GPR sont bien mieux que 8, et nous le verrons de façon concrète
plus loin dans cet article.
5) Calculs flottants, SSE et SSE2
Pourquoi plus de registres SSE/SSE2 et pas plus de registres flottants
x87 ?
La raison est assez simple : suivant la voie ouverte par Intel, AMD veut
tout simplement abandonner le x87. L'x87 est vieillissant, et surtout
de manipulation assez peu pratique car les registres sont gérés
sous la forme d'une pile et non de registres. Adieu donc le code x87,
au profit du code SSE/SSE2 et de ses 16 registres. Corollaire de cet abandon
: les intructions MMX de première génération, qui
opéraient sur ces mêmes registres x87, sont également
abandonnés. Là encore, les instructions MMX passeront par
les registres SSE/SSE2.
Cela dit, les K7/K8 ne sont pas réputés pour briller particulièrement en SSE/SSE2, surtout face au Pentium 4 qui a été dessiné pour fournir des performances optimales sur ces deux jeux d'instructions. Cette différence de performance provient de l'architecture même des unités de calcul flottant des deux processeurs. Les unités de calculs comprennent des circuits logiques dédiés à un type d'opération. Ces circuits obéissent à des schémas logiques classiques, citons par exemple l'arbre de Wallace qui est une méthode d'organisation des portes logiques pour mener une opération telle qu'une addition ou une multiplication.
Le Pentium 4 ayant été dessiné pour prendre en charge les opérations flottantes sur des registres 128 bits, les arbres de Wallace de ses circuits logiques ont une largeur de 128 bits, ce qui signifient qu'ils sont capables de traiter en une passe une multiplication ou une addition 128 bits. Attention, cela ne veut pas dire que de telles opérations s'effectuent en un seul cycle, car ces opérations restent soumises au découpage du pipeline. Le traitement en une passe signifie qu'un seul passage dans l'arbre de Wallace sera nécessaire afin d'effectuer une opération sur des registres 128 bits.
Dans le K8, les unités de calculs flottants ont été dessinées pour fournir des performances maximales sur des registres x87, soit 80 bits. Les arbres de Wallace ont donc une largeur de 80 bits, ce qui nécessite deux passes pour effectuer une opération sur des registres 128 bits.
Cela explique que les performances SSE et SSE2 du K8 soient, dans la
plupart des cas, inférieures à celles obtenues sur un Pentium
4. Cela signifie-t-il pour autant que le K8 va perdre sa suprématie
en calculs flottants lorsqu'il est utilisé dans un environnement
64 bits ? Les calculs flottants vont-ils donc être moins rapide
en mode 64 bits ? En fait, cela dépendra, mais dans la plupart
des cas, la réponse est non.
Pour en comprendre la raison, il faut examiner la façon dont les
compilateurs vont créer du code SSE à partir de calculs
flottants classiques. Une opération flottante sera transformée
en instruction SSE de type scalaire, c'est-à-dire
n'opérant que sur une seule partie de 32 ou 64 bits du registre
128 bits. Ces instructions scalaires sont certes moins efficaces que les
instructions vectorielles, qui permettent d'effectuer
la même opération sur toutes les parties du registre 128
bits (c'est d'ailleurs la raison d'être de la technique SIMD, Single
Instruction Multiple Data). Mais les instructions scalaires n'opérant
pas sur les 128 bits du registre, elles peuvent s'effectuer en une seule
passe sur un arbre de Wallace de 80 bits, ce qui redonne toute leur performance
aux unités de calcul du K8.
En résumé, le K8 souffre en SSE dès lors que des
instructions vectorielles sont utilisées, mais il se comporte de
façon très performantes sur les instructions scalaires.
A la différence du Pentium 4, qui digère de la même
façon les deux types d'instructions.
A la faveur du K8, les compilateurs actuels ne sont capables de générer
que des instructions scalaires. L'utilisation d'instruction vectorielles
passe par une phase préalable de vectorisation du code, qui à
l'heure actuelle n'est faite efficacement que par un programmeur humain.
6) Le code 64 bits
Comme vous l'avez compris, nous verrons donc dans un code 64 bits un jeu d'instruction entier opérant que seize GPR 64 bits, et des instructions SSE/SSE2 scalaires opérant quant à elles sur 16 registres 128 bits.
Une question importante concerne la taille du code généré.
Le code généré est plus gros en 64 bits, un code
plus gros présente de nombreux désavantages. D'une part
il se décode plus lentement, et d'autre part il remplit plus vite
le cache code du processeur.
Du code 64 bits tend en effet à générer des instructions
de plus grande taille que du code 32 bits, essentiellement parce que les
opérandes sont deux fois plus grandes (adresses mémoire
et valeurs immédiates sont codées sur 64 bits au lieu de
32). De plus, dans le cas particulier de l'AMD64, les instructions 64
bits utilisent un préfixe, ce qui augmente la taille des instructions
d'un octets supplémentaire. De plus, l'utilisation du SSE/SSE2
en lieu et place des instructions x87 tend à rendre le code encore
plus volumineux, les instructions SSE/SSE2 étant elles aussi préfixée.
AMD a cependant prévu quelques astuces afin de limiter la taille
du code 64 bits. Voyons cela sur un exemple concret.
Supposons que nous voulions copier la valeur 1 dans un registre, soit
en pseudo-code :
mov register, 1
Si le registre fait une taille de 32 bits, la valeur qui lui sera affectée sera elle aussi codée sur 32 bits. Ce qui nous donne en notation hexadécimale :
mov eax, 00000001h
Si le registre fait 64 bits, nous aurons alors :
mov rax, 0000000000000001h
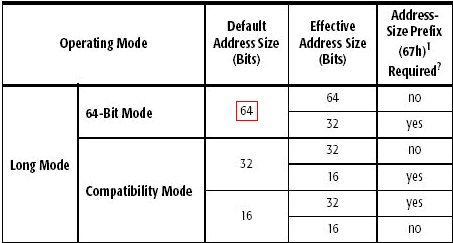
Vous l'avez compris, le "1" 64 bits s'encode sur beaucoup plus d'octets que le "1" 32 bits, et la taille de l'instruction 64 bits est au moins 4 octets plus grosse que son pendant 32 bits. Il est d'autant moins intéressant d'encoder la valeur en 64 bits que le besoin actuel d'entiers 64 bits est encore anecdotique. La solution retenue par AMD est dans le tableau des modes d'exploitation, dont nous avons retenu la partie concernée :

Elle consiste ainsi à définir la taille par défaut
des opérandes à non plus 64 mais 32 bits. Bien entendu l'utilisation
d'une opérande sous sa forme 64 bits est possible, mais elle nécessite
alors un préfixe pour spécifier que c'est bien la forme
64 bits que l'on souhaite pour cette instruction. Notre instruction devient
donc :
mov rax, 00000001h
L'instruction 64 bits fait un donc un seul octets de plus que son équivalent 32 bits, cet octet étant le préfixe REX indiquant qu'il s'agit là d'une instruction 64 bits.
A noter qu'en pratique, les compilateurs modernes agissent intelligemment, et encodent les opérandes sous leur forme canonique. Ainsi, l'instruction IA32 add ebx,8 est encodée sous la forme 83 C3 08 et non 83 C3 08 00 00 00. De la même façon, l'équivalent AMD64 de cette instruction : mov rbx,8 deviendra 48 83 C3 08. Le préfixe 48 correspond ici au registre REX.
En ce qui concerne les opérandes faisant intervenir une adresse mémoire, le choix est plus délicat. L'utilisation d'adresses mémoire de plus de 32 bits risque de s'avérer beaucoup plus courant que des opérandes 64 bits, comme c'est le cas précédemment. AMD a donc choisi la voie inverse : la taille des adresses mémoire fait 64 bits par défaut, et la forme 32 bits nécessite de préfixer l'instruction. Ainsi, la taille par défaut des pointeurs C/C++ est 64 bits.
On peut estimer qu'un code 64 bits sera en moyenne entre 20 et 25% plus
volumineux que'un code IA32 équivalent. Mais il faut également
tenir compte que l'utilisation de seize GPR a tendance à diminuer
le nombre d'instructions, ce qui pour des fonctions assez complexes peut
rendre le code 64 bits finalement plus court que son équivalent
IA32. L'inflation de la taille du code dépendra donc fortement
du type d'application, et également du compilateur.
En outre, il faut également noter que le K8 est bien armé pour encaisser l'inflation de la taille du code généré, en particulier :
- les trois décodeurs qui travaillent en parallèle pour
alimenter les unités d'exécution.
- un cache code de premier niveau de 64Ko.