Etude de l'architecture Atom
Parlons maintenant de l’architecture interne des processeurs Diamondville et Silverthorne. Celle-ci a été conçue de zéro, en partant tout de même de blocs logiques existants. Inutile donc de chercher une quelconque similitude avec le Pentium 4, le Pentium M ou le Core 2 à ce niveau. A première vue lorsqu’on étudie pour la première fois cette architecture, de nombreux choix paraissent déroutants et même incompréhensibles.
Pour mieux les comprendre, il faut revenir à la genèse de ces processeurs, car ceux-ci n’ont en réalité jamais été conçus pour intégrer des MID et autres Netbooks. Le projet commence en 2004. A cette époque, il est question de créer une nouvelle architecture simplifiée pour créer des processeurs dotés de plusieurs dizaines de cœurs dans un seul die (morceau de silicium). Ceux-ci sont alors prévus pour 2008. Hélas, le développement de ce nouveau cœur n’a pas suivi les prévisions : les ingénieurs se sont vite retrouvés avec un cœur beaucoup trop gros (47 millions de transistors par coeur, pour rappel) et trop gourmand en énergie (plus de 120 Watts pour un modèle doté de 32 cœurs). Le projet à donc été mis en suspend et le cœur « recyclé » comme processeur low-cost dédié aux PC ultra-mobiles. Bel exemple de reconversion.
- Le coeur : un assemblage simple
L’architecture Atom telle qu’elle est aujourd’hui trahit son passé, et tout d’abord de par son mode de fonctionnement : il s’agit d’une architecture In Order, ou les instructions sont traitées dans l’ordre d’arrivée, sans ré-ordonnancement pour améliorer l’efficacité du pipeline. Pour rappel, la dernier processeur Intel à utiliser du In Order était le Pentium, sorti en 1993. Depuis le Pentium Pro, un moteur de traitement Out-Of-Order (OOO) a été mis en place. C’était d’ailleurs la grande évolution de l’époque : au cœur du processeur, le flot d’instructions n’était plus systématiquement bloqué lorsque les données à traiter n’étaient pas prêtes. Ceci se traduisait par une augmentation de la vitesse de traitement et par quelques étages supplémentaires dans le pipeline.
Avec l’Atom, Intel a choisi de supprimer le complexe moteur OOO, probablement pour diminuer au maximum la taille du chip, et donc l’énergie consommée. Jusque là, ce choix radical reste compréhensible. Ce qui l’est beaucoup moins, c’est la taille du pipeline : 16 étages ! D’autant plus étrange qu’une architecture In Order se contente souvent de 5 à 8 étages pour minimiser la perte de temps lorsqu’une pénalité survient. Le cheminement du flot de données est le suivant :
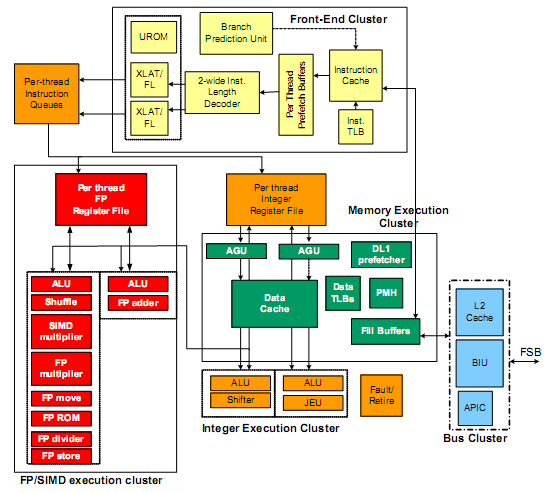

Dans le Front-End (FEC), le flot d'instructions en provenant du cache L1I (32 Ko) passe par les buffers de prefetch avant d'arriver dans l'unité de décodage qui inclut deux décodeurs hardware. Ceux-ci sont capables de décoder deux instructions par cycle d'horloge, que ce soit sur le même thread ou sur deux threads différents. Une fois décodées, ces instructions passent ensuite dans la queue d'instructions du thread (16 entrées max * 2 threads) auxquelles elles appartiennent, afin de parvenir dans l'un des deux "clusters" d'exécutions. Soit le « FP/SIMD execution Cluster » (FPC), soit le « Integer Execution Cluster » (IEC). Les données, quant à elles, sont obtenues du cache de donnée L1 situé dans le « Memory Cluster Execution » (MEC), ou via le cache L2 ou la mémoire par l’intermédiaire du « Bus Interface Cluster » (BIC). Mais revenons quelques instants aux clusters d’exécutions.
 |
Côté entier, on fait dans la simplicité avec deux unités ALU 64 bit. L’une inclut le décalage (shift), l’autre gère les sauts (jump). Ces unités ne traitent pas les divisions et multiplications pour limiter leurs complexités et ces instructions sont sont en fait dérivées vers les unités FP. Côté FP justement, on trouve deux unités, la première, très simple, se contente d’un ALU et d’un additionneur (FP ADD). La seconde par contre est nettement plus complexe puisqu’elle intègre le SIMD, les multiplications et les division scalaires en 32 et 64 bits. Les instructions vectorielles sur 128 bits sont traitées en combinant les deux unités FP/SIMD. Ces unités peuvent donc exécuter, au mieux, soit deux instructions 64 bit, soit une instruction 128 bit par cycle. Intel a fait le parti de ne garder qu'une seule unité d’exécution complexe, ce qui à du sens vu le type d’applications basiques destinées à être exécutées sur les processeurs Atom. Tout est d’ailleurs conçu dans ce sens puisque cette architecture est optimisée pour les instructions les plus courantes, allant même jusqu'à les optimiser (les instructions basiques incluant un accès mémoire sont traitées en une seule µops), tout en faisant l’impasse (ou presque) sur les instructions complexes. |
Les données fournies par Intel justifient cette organisation :
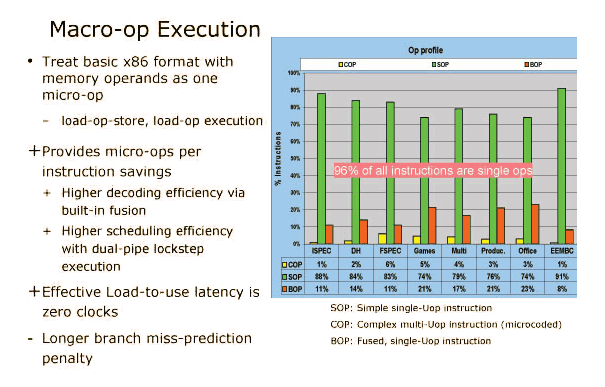
Ainsi, selon ces chiffres, 96% des instructions (SOP et BOP) seront traitées en une seule opération. D’autres améliorations du même type sont également prévues afin de limiter la dégradation de performance en maximisant l’utilisation du pipeline. La plus évidente est bien sur l’utilisation de l’Hyperthreading qui, en laissant au système d’exploitation la gestion de deux threads, permet de réduire les « bulles » dans le pipeline. Vu l’architecture In Order et à 16 étages utilisées ici, ce type de technologie devrait offrir des gains nettement supérieurs à celui que nous avons pu observer sur Pentium 4. Nous vérifierons cela dans la page suivante.
- Les caches
Dans une architecture In-Order, la disponibilité des données au sein du cœur est capitale. Car si les données ne sont pas disponibles, c’est tout le processeur qui doit attendre leurs disponibilités sans pouvoir rien faire d’autre. D’où l’importance de maintenir l'efficacité des caches la plus haute possible.
Commençons par le cache L1. Celui est composé d’un cache d’instructions de 32 Ko et d’un cache de données de 24 Ko. Cette répartition asymétrique est très rare et l’explication que nous allons vous donner concernant cette dissymétrie n’a pas été confirmée par Intel. Toutefois, nous ne voyons pas d’autre explication logique. Pour stocker un bit de mémoire cache, il faut 6 transistors. C’est le cas pour la majorité des caches qui équipent les processeurs du marché. Toutefois, on constate que le taille d’une cellule de cache (pour stocker un bit donc) est de 0.382 µm² contre 0.346 µm² pour le Core 2, par exemple.
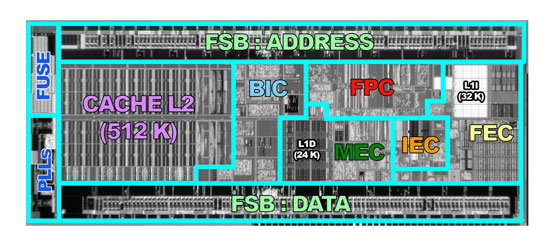
L’explication se trouve dans la documentation : les cellules de cache L1 des CPU Atom nécessitent 8 transistors au lieu de 6. Cette répartition semble avoir été choisie (encore une fois) dans un souci d’économie d’énergie, car un cache 8T (8 transistors/bit) conserve l’information stockée avec une tension d’alimentation plus faible qu’un cache 6T. On peut donc penser que, lors du design du chip, Intel a tenté de diminuer au maximum la tension d’alimentation et a été limité par les cellules 6T. En conséquence, le remplacement vers des cellules 8T (+20%) a été choisi, mais comme le design était déjà à un stade avancé, la place physique disponible au cœur du die n’a pas pu être augmentée et à du être réduite de 20%, ce qui provoque ce passage de 32 Ko à 24 Ko. CQFD.
Côté L2, les choses sont nettement plus simples puisqu’on trouve un cache 8-way de 512 Ko relativement similaire à celui qu’on peut trouver sur un Core 2. Bien entendu, il dispose de technologies d’économie d’énergie et est par exemple capable de ne fonctionne qu’en 2-way sur des applications peu gourmandes, ce qui revient à l'amputer des trois-quarts de sa capacité.
- Economies d'energie
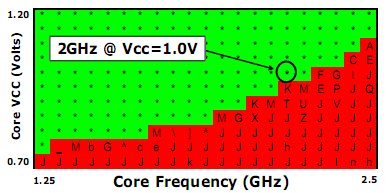
Les processeurs Atom disposent de nombreuses technologies destinées à diminuer au maximum la tension d’alimentation et donc, la consommation électrique. L’exemple du cache L1 cité ci-dessus en est un excellent exemple, mais il y en a d’autres. Ces CPU sont ainsi destinés à être alimenté en 1.05 Volts, mais leur pipeline peut supporter une fréquence maximale de 2.5 GHz sous 1.15 Volts. De même, à 1.25 GHz, une tension de 0.75 Volt est suffisante pour garantir le bon fonctionnement, comme on peut le voir sur ce tableau :
Mieux, les Silverthorne inaugurent un nouveau mode de veille profonde baptisé C6 qui maintient le processeur à un état de veille très profonde. Lors que le CPU est en mode C6, la tension d’alimentation tombe à 0.3 Volt et seul 21 broches du processeur restent actives. L’état du pipeline et les instructions en cours de traitement sont alors stockées dans une petit mémoire cache de 10.5 Ko. A ce stade, le processeur ne consomme plus que quelques mW destinés à alimenter la SRAM et la circuiterie minimale pour "reveiller" le CPU. Mais la véritable prouesse reste le temps mis à « réveiller » un CPU en mode de veille profonde C6 : moins de 100 microsecondes ! Intel indique ainsi qu’en utilisation normale, un Silverthorne peut passer plus de 90% du temps en mode C6, et ce de manière totalement transparente pour l’utilisateur. Dans la pratique, ceci permet donc de faire baisser le TDP d’un processeur spécifié à 2 Watts à moins qu’un Watt.
Enfin, l’une des autres nouveautés provient du FSB. Depuis le Pentium Pro, tous les processeurs d’Intel ont adopté le mode de signalisation GTL/AGTL+. En clair, il s’agit de mettre une résistance dite « pull-down » à chaque bout du signal afin d’augmenter le courant qui circule sur le bus. Le signal est donc plus « net » et il devient possible d’augmenter fortement la fréquence tout en conservant l’intégrité des données. En schématisant à la hache, on peut comparer cela aux bouchons qu’on mettait autrefois sur les réseaux BNC. Auparavant, le CMOS classique était de mise, lorsque les fréquences de bus étaient faibles. Avec Silverthorne, Intel a trouvé le moyen de faire fonctionner son processeur en mode GTL ou CMOS, tout en préservant l’intégrité des données. Cette modification entraine un diminution de moitié de la consommation du bus. Il faut toutefois un chipset capable de fonctionner en mode CMOS et, à l’heure actuelle, seul le Poulsbo (US15) en est capable.